

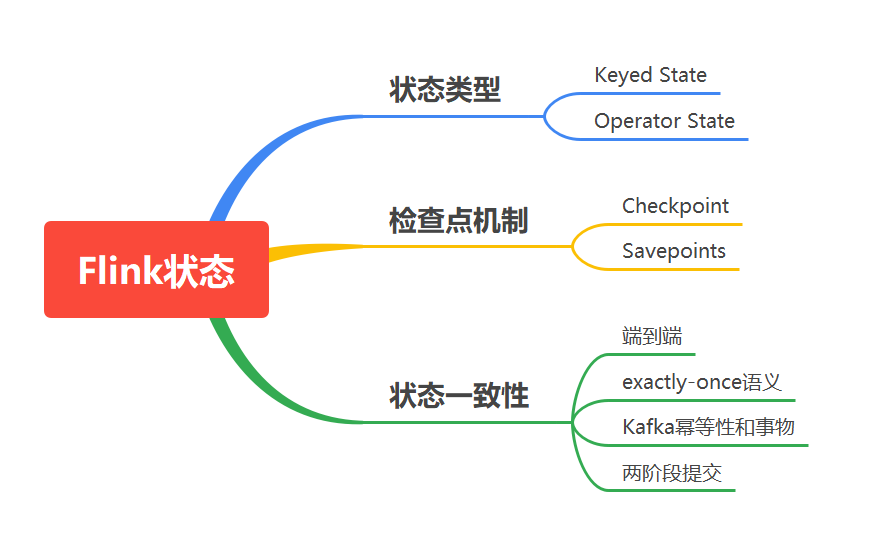
一、前言
有状态的计算是流处理框架要实现的重要功能,因为稍复杂的流处理场景都需要记录状态,然后在新流入数据的基础上不断更新状态。下面的几个场景都需要使用流处理的状态功能:
数据流中的数据有重复,想对重复数据去重,需要记录哪些数据已经流入过应用,当新数据流入时,根据已流入过的数据来判断去重。
检查输入流是否符合某个特定的模式,需要将之前流入的元素以状态的形式缓存下来。比如,判断一个温度传感器数据流中的温度是否在持续上升。
对一个时间窗口内的数据进行聚合分析,分析一个小时内某项指标的75分位或99分位的数值。
一个状态更新和获取的流程如下图所示,一个算子子任务接收输入流,获取对应的状态,根据新的计算结果更新状态。一个简单的例子是对一个时间窗口内输入流的某个整数字段求和,那么当算子子任务接收到新元素时,会获取已经存储在状态中的数值,然后将当前输入加到状态上,并将状态数据更新。

二、状态类型
Flink有两种基本类型的状态:托管状态(Managed State)和原生状态(Raw State)。
两者的区别:Managed State是由Flink管理的,Flink帮忙存储、恢复和优化,Raw State是开发者自己管理的,需要自己序列化。
具体区别有:
- 从状态管理的方式上来说,Managed State由Flink Runtime托管,状态是自动存储、自动恢复的,Flink在存储管理和持久化上做了一些优化。当横向伸缩,或者说修改Flink应用的并行度时,状态也能自动重新分布到多个并行实例上。Raw State是用户自定义的状态。
- 从状态的数据结构上来说,Managed State支持了一系列常见的数据结构,如ValueState、ListState、MapState等。Raw State只支持字节,任何上层数据结构需要序列化为字节数组。使用时,需要用户自己序列化,以非常底层的字节数组形式存储,Flink并不知道存储的是什么样的数据结构。
- 从具体使用场景来说,绝大多数的算子都可以通过继承Rich函数类或其他提供好的接口类,在里面使用Managed State。Raw State是在已有算子和Managed State不够用时,用户自定义算子时使用。
对Managed State继续细分,它又有两种类型:Keyed State和Operator State。
为了自定义Flink的算子,可以重写Rich Function接口类,比如RichFlatMapFunction。使用Keyed State时,通过重写Rich Function接口类,在里面创建和访问状态。对于Operator State,还需进一步实现CheckpointedFunction接口。
2.1、Keyed State
Flink 为每个键值维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的key。因此,具有相同key的所有数据都会访问相同的状态。
需要注意的是键控状态只能在 KeyedStream 上进行使用,可以通过 stream.keyBy(...) 来得到 KeyedStream 。
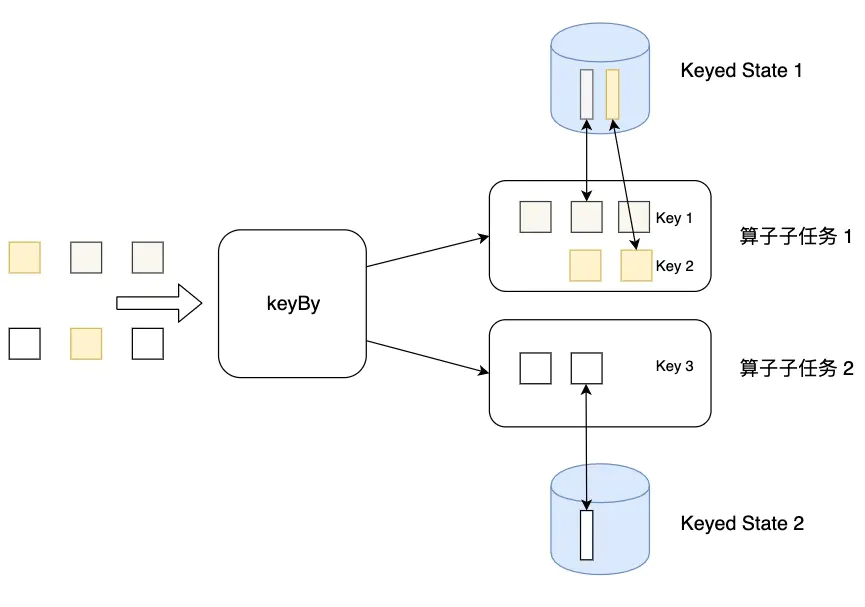
Flink 提供了以下数据格式来管理和存储键控状态 (Keyed State):
- ValueState:存储单值类型的状态。可以使用 update(T) 进行更新,并通过 T value() 进行检索。
- ListState:存储列表类型的状态。可以使用 add(T) 或 addAll(List) 添加元素,update(T)进行更新;并通过 get() 获得整个列表。
- ReducingState:用于存储经过 ReduceFunction 计算后的结果,使用 add(T) 增加元素。
- AggregatingState:用于存储经过 AggregatingState 计算后的结果,使用 add(IN) 添加元素。
- FoldingState:已被标识为废弃,会在未来版本中移除,官方推荐使用 AggregatingState 代替。
- MapState:维护 Map 类型的状态,get获取,put更新,contains判断包含,remove移除元素。
public class ListStateDemo extends RichFlatMapFunction<Tuple2<String, Long>,List<Tuple2<String, Long>>>{
private transient ListState<Tuple2<String, Long>> listState;
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
ListStateDescriptor<Tuple2<String, Long>> listStateDescriptor = new ListStateDescriptor(
"listState",
TypeInformation.of(new TypeHint<Tuple2<String, Long>>() {})
);
listState = getRuntimeContext().getListState(listStateDescriptor);
}
@Override
public void flatMap(Tuple2<String, Long> value, Collector<List<Tuple2<String, Long>>> out) throws Exception {
List<Tuple2<String, Long>> currentListState = Lists.newArrayList(listState.get().iterator());
currentListState.add(value);
listState.update(currentListState);
out.collect(currentListState);
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
DataStream<Tuple2<String, Long>> dataStream = senv.fromElements(
Tuple2.of("a", 50L),Tuple2.of("a", 60L),Tuple2.of("a", 70L),
Tuple2.of("b", 50L),Tuple2.of("b", 60L),Tuple2.of("b", 70L),
Tuple2.of("c", 50L),Tuple2.of("c", 60L),Tuple2.of("c", 70L)
);
dataStream
.keyBy(0)
.flatMap(new ListStateDemo())
.print();
senv.execute(ListStateDemo.class.getSimpleName());
}
}
2.2、Operator State
Operator State可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。
算子状态不能由相同或不同算子的另一个实例访问。
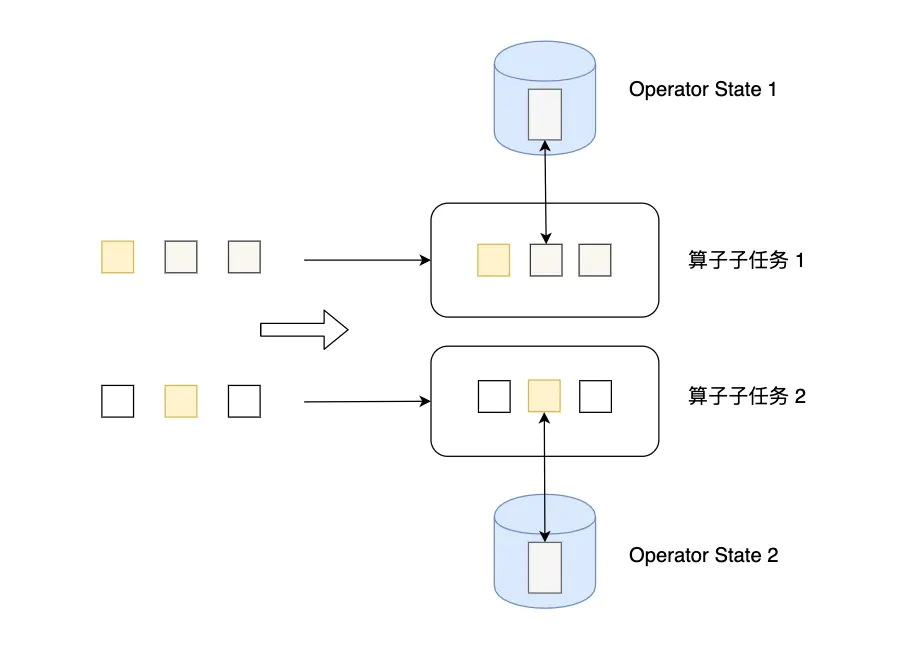
Flink为算子状态提供三种基本数据结构:
- ListState:存储列表类型的状态。
- UnionListState:存储列表类型的状态,与 ListState 的区别在于:如果并行度发生变化,ListState 会将该算子的所有并发的状态实例进行汇总,然后均分给新的 Task;而 UnionListState 只是将所有并发的状态实例汇总起来,具体的划分行为则由用户进行定义。
- BroadcastState:用于广播的算子状态。如果一个算子有多项任务,而它的每项任务状态又都相同,那么这种特殊情况最适合应用广播状态。
假设此时不需要区分监控数据的类型,只要有监控数据超过阈值并达到指定的次数后,就进行报警:
public class OperateStateDemo extends RichFlatMapFunction<Tuple2<String, Long>, List<Tuple2<String, Long>>>
implements CheckpointedFunction{
private final int threshold;
private transient ListState<Tuple2<String, Long>> checkpointedState;
private List<Tuple2<String, Long>> bufferedElements;
public OperateStateDemo(int threshold) {
this.threshold = threshold;
this.bufferedElements = new ArrayList<>();
}
@Override
public void flatMap(Tuple2<String, Long> value, Collector<List<Tuple2<String, Long>>> out) throws Exception {
bufferedElements.add(value);
if(bufferedElements.size() == threshold) {
out.collect(bufferedElements);
bufferedElements.clear();
}
}
/**
* 进行checkpoint快照
* @param context
* @throws Exception
*/
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
checkpointedState.clear();
for(Tuple2<String, Long> element : bufferedElements) {
checkpointedState.add(element);
}
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<Tuple2<String, Long>> listStateDescriptor = new ListStateDescriptor(
"listState",
TypeInformation.of(new TypeHint<Tuple2<String, Long>>() {})
);
checkpointedState = context.getOperatorStateStore().getListState(listStateDescriptor);
// 如果是故障恢复
if(context.isRestored()) {
for(Tuple2<String, Long> element : checkpointedState.get()) {
bufferedElements.add(element);
}
checkpointedState.clear();
}
}
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
senv.getCheckpointConfig().setCheckpointInterval(500);
DataStream<Tuple2<String, Long>> dataStream = senv.fromElements(
Tuple2.of("a", 50L),Tuple2.of("a", 60L),Tuple2.of("a", 70L),
Tuple2.of("b", 50L),Tuple2.of("b", 60L),Tuple2.of("b", 70L),
Tuple2.of("c", 50L),Tuple2.of("c", 60L),Tuple2.of("c", 70L)
);
dataStream
.flatMap(new OperateStateDemo(2))
.print();
senv.execute(OperateStateDemo.class.getSimpleName());
}
}
三、状态横向扩展
状态的横向扩展问题主要是指修改Flink应用的并行度,确切的说,每个算子的并行实例数或算子子任务数发生了变化,应用需要关停或启动一些算子子任务,某份在原来某个算子子任务上的状态数据需要平滑更新到新的算子子任务上。
Flink的Checkpoint就是一个非常好的在各算子间迁移状态数据的机制。算子的本地状态将数据生成快照(snapshot),保存到分布式存储(如HDFS)上。横向伸缩后,算子子任务个数变化,子任务重启,相应的状态从分布式存储上重建(restore)。

对于Keyed State和Operator State这两种状态,他们的横向伸缩机制不太相同。由于每个Keyed State总是与某个Key相对应,当横向伸缩时,Key总会被自动分配到某个算子子任务上,因此Keyed State会自动在多个并行子任务之间迁移。对于一个非KeyedStream,流入算子子任务的数据可能会随着并行度的改变而改变。如上图所示,假如一个应用的并行度原来为2,那么数据会被分成两份并行地流入两个算子子任务,每个算子子任务有一份自己的状态,当并行度改为3时,数据流被拆成3支,或者并行度改为1,数据流合并为1支,此时状态的存储也相应发生了变化。对于横向伸缩问题,Operator State有两种状态分配方式:一种是均匀分配,另一种是将所有状态合并,再分发给每个实例上。
四、检查点机制
为了使 Flink 的状态具有良好的容错性,Flink 提供了检查点机制 (CheckPoints) 。通过检查点机制,Flink 定期在数据流上生成 checkpoint barrier ,当某个算子收到 barrier 时,即会基于当前状态生成一份快照,然后再将该 barrier 传递到下游算子,下游算子接收到该 barrier 后,也基于当前状态生成一份快照,依次传递直至到最后的 Sink 算子上。当出现异常后,Flink 就可以根据最近的一次的快照数据将所有算子恢复到先前的状态。
4.1、开启检查点 (checkpoint)
默认情况下 checkpoint 是禁用的。通过调用 StreamExecutionEnvironment 的 enableCheckpointing(n) 来启用 checkpoint,里面的 n 是进行 checkpoint 的间隔,单位毫秒。
Checkpoint是Flink实现容错机制最核心的功能,它能够根据配置周期性地基于Stream中各个Operator的状态来生成Snapshot,从而将这些状态数据定期持久化存储下来,当Flink程序一旦意外崩溃时,重新运行程序时可以有选择地从这些Snapshot进行恢复,从而修正因为故障带来的程序数据状态中断。这里,我们简单理解一下Flink Checkpoint机制,如官网下图所示:

Checkpoint指定触发生成时间间隔后,每当需要触发Checkpoint时,会向Flink程序运行时的多个分布式的Stream Source中插入一个Barrier标记,这些Barrier会根据Stream中的数据记录一起流向下游的各个Operator。当一个Operator接收到一个Barrier时,它会暂停处理Steam中新接收到的数据记录。因为一个Operator可能存在多个输入的Stream,而每个Stream中都会存在对应的Barrier,该Operator要等到所有的输入Stream中的Barrier都到达。当所有Stream中的Barrier都已经到达该Operator,这时所有的Barrier在时间上看来是同一个时刻点(表示已经对齐),在等待所有Barrier到达的过程中,Operator的Buffer中可能已经缓存了一些比Barrier早到达Operator的数据记录(Outgoing Records),这时该Operator会将数据记录(Outgoing Records)发射(Emit)出去,作为下游Operator的输入,最后将Barrier对应Snapshot发射(Emit)出去作为此次Checkpoint的结果数据。
Checkpoint 其他的属性包括:
- 精确一次(exactly-once)对比至少一次(at-least-once):你可以选择向 enableCheckpointing(long interval, CheckpointingMode mode) 方法中传入一个模式来选择使用两种保证等级中的哪一种。对于大多数应用来说,精确一次是较好的选择。至少一次可能与某些延迟超低(始终只有几毫秒)的应用的关联较大。
- checkpoint 超时:如果 checkpoint 执行的时间超过了该配置的阈值,还在进行中的 checkpoint 操作就会被抛弃。
- checkpoints 之间的最小时间:该属性定义在 checkpoint 之间需要多久的时间,以确保流应用在 checkpoint 之间有足够的进展。如果值设置为了 5000,无论 checkpoint 持续时间与间隔是多久,在前一个 checkpoint 完成时的至少五秒后会才开始下一个 checkpoint。
- 并发 checkpoint 的数目: 默认情况下,在上一个 checkpoint 未完成(失败或者成功)的情况下,系统不会触发另一个 checkpoint。这确保了拓扑不会在 checkpoint 上花费太多时间,从而影响正常的处理流程。不过允许多个 checkpoint 并行进行是可行的,对于有确定的处理延迟(例如某方法所调用比较耗时的外部服务),但是仍然想进行频繁的 checkpoint 去最小化故障后重跑的 pipelines 来说,是有意义的。
- externalized checkpoints: 你可以配置周期存储 checkpoint 到外部系统中。Externalized checkpoints 将他们的元数据写到持久化存储上并且在 job 失败的时候不会被自动删除。这种方式下,如果你的 job 失败,你将会有一个现有的 checkpoint 去恢复。更多的细节请看 Externalized checkpoints 的部署文档。
- 在 checkpoint 出错时使 task 失败或者继续进行 task:他决定了在 task checkpoint 的过程中发生错误时,是否使 task 也失败,使失败是默认的行为。 或者禁用它时,这个任务将会简单的把 checkpoint 错误信息报告给 checkpoint coordinator 并继续运行。
- 优先从 checkpoint 恢复(prefer checkpoint for recovery):该属性确定 job 是否在最新的 checkpoint 回退,即使有更近的 savepoint 可用,这可以潜在地减少恢复时间(checkpoint 恢复比 savepoint 恢复更快)。
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
// 每 1000ms 开始一次 checkpoint
env.enableCheckpointing(1000);
// 高级选项:
// 设置模式为精确一次 (这是默认值)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// 确认 checkpoints 之间的时间会进行 500 ms
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
// Checkpoint 必须在一分钟内完成,否则就会被抛弃
env.getCheckpointConfig().setCheckpointTimeout(60000);
// 同一时间只允许一个 checkpoint 进行
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
// 开启在 job 中止后仍然保留的 externalized checkpoints
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// 允许在有更近 savepoint 时回退到 checkpoint
env.getCheckpointConfig().setPreferCheckpointForRecovery(true);
保存多个Checkpoint
默认情况下,如果设置了Checkpoint选项,则Flink只保留最近成功生成的1个Checkpoint,而当Flink程序失败时,可以从最近的这个Checkpoint来进行恢复。但是,如果我们希望保留多个Checkpoint,并能够根据实际需要选择其中一个进行恢复,这样会更加灵活,比如,我们发现最近4个小时数据记录处理有问题,希望将整个状态还原到4小时之前。
Flink可以支持保留多个Checkpoint,需要在Flink的配置文件conf/flink-conf.yaml中,添加如下配置,指定最多需要保存Checkpoint的个数:
state.checkpoints.num-retained: 20
保留了最近的20个Checkpoint。如果希望会退到某个Checkpoint点,只需要指定对应的某个Checkpoint路径即可实现。
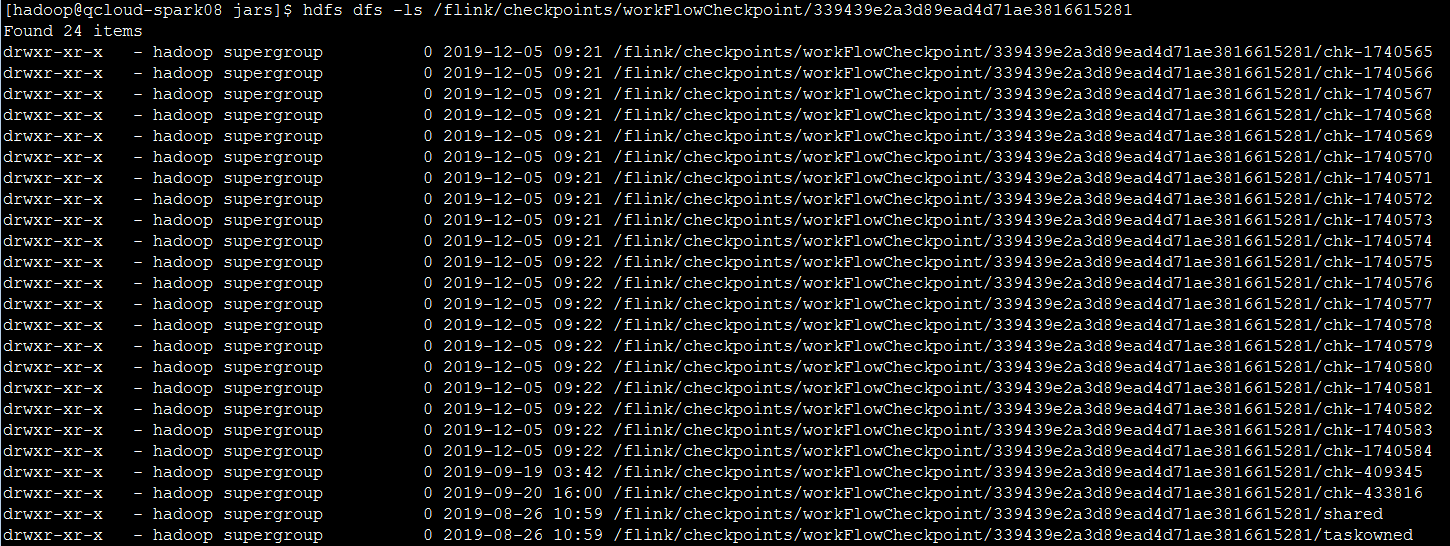
从Checkpoint进行恢复
从指定的checkpoint处启动,最近的一个/flink/checkpoints/workFlowCheckpoint/339439e2a3d89ead4d71ae3816615281/chk-1740584启动,通常需要先停掉当前运行的flink-session,然后通过命令启动:
../bin/flink run -p 10 -s /flink/checkpoints/workFlowCheckpoint/339439e2a3d89ead4d71ae3816615281/chk-1740584/_metadata -c com.code2144.helper_wink-1.0-SNAPSHOT.jar
可以把命令放到脚本里面,每次直接执行checkpoint恢复脚本即可:
4.2、保存点机制 (Savepoints)
保存点机制 (Savepoints)是检查点机制的一种特殊的实现,它允许通过手工的方式来触发 Checkpoint,并将结果持久化存储到指定路径中,主要用于避免 Flink 集群在重启或升级时导致状态丢失。示例如下:
# 触发指定id的作业的Savepoint,并将结果存储到指定目录下
bin/flink savepoint :jobId [:targetDirectory]
手动savepoint
/app/local/flink-1.6.2/bin/flink savepoint 0409251eaff826ef2dd775b6a2d5e219 [hdfs://bigdata/path]
成功触发savepoint通常会提示:Savepoint completed. Path: hdfs://path...:
手动取消任务
与checkpoint异常停止或者手动Kill掉不一样,对于savepoint通常是我们想要手动停止任务,然后更新代码,可以使用flink cancel ...命令:
/app/local/flink-1.6.2/bin/flink cancel 0409251eaff826ef2dd775b6a2d5e219
从指定savepoint启动job
bin/flink run -p 8 -s hdfs:///flink/savepoints/savepoint-567452-9e3587e55980 -c com.code2144.helper_workflow.HelperWorkFlowStreaming jars/BSS-ONSS-Flink-1.0-SNAPSHOT.jar
五、状态后端
Flink 提供了多种 state backends,它用于指定状态的存储方式和位置。
状态可以位于 Java 的堆或堆外内存。取决于 state backend,Flink 也可以自己管理应用程序的状态。为了让应用程序可以维护非常大的状态,Flink 可以自己管理内存(如果有必要可以溢写到磁盘)。默认情况下,所有 Flink Job 会使用配置文件 flink-conf.yaml 中指定的 state backend。
但是,配置文件中指定的默认 state backend 会被 Job 中指定的 state backend 覆盖。
5.1、状态管理器分类
MemoryStateBackend
默认的方式,即基于 JVM 的堆内存进行存储,主要适用于本地开发和调试。
FsStateBackend
基于文件系统进行存储,可以是本地文件系统,也可以是 HDFS 等分布式文件系统。 需要注意而是虽然选择使用了 FsStateBackend ,但正在进行的数据仍然是存储在 TaskManager 的内存中的,只有在 checkpoint 时,才会将状态快照写入到指定文件系统上。
RocksDBStateBackend
RocksDBStateBackend 是 Flink 内置的第三方状态管理器,采用嵌入式的 key-value 型数据库 RocksDB 来存储正在进行的数据。等到 checkpoint 时,再将其中的数据持久化到指定的文件系统中,所以采用 RocksDBStateBackend 时也需要配置持久化存储的文件系统。之所以这样做是因为 RocksDB 作为嵌入式数据库安全性比较低,但比起全文件系统的方式,其读取速率更快;比起全内存的方式,其存储空间更大,因此它是一种比较均衡的方案。
5.2、配置方式
Flink 支持使用两种方式来配置后端管理器:
第一种方式:基于代码方式进行配置,只对当前作业生效:
// 配置 FsStateBackend
env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints"));
// 配置 RocksDBStateBackend
env.setStateBackend(new RocksDBStateBackend("hdfs://namenode:40010/flink/checkpoints"));
配置 RocksDBStateBackend 时,需要额外导入下面的依赖:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_2.11</artifactId>
<version>1.9.0</version>
</dependency>
第二种方式:基于 flink-conf.yaml 配置文件的方式进行配置,对所有部署在该集群上的作业都生效:
state.backend: filesystem
state.checkpoints.dir: hdfs://namenode:40010/flink/checkpoints
六、状态一致性
6.1、端到端(end-to-end)
在真实应用中,流处理应用除了流处理器以外还包含了数据源(例如 Kafka)和输出到持久化系统。
端到端的一致性保证,意味着结果的正确性贯穿了整个流处理应用的始终;每一个组件都保证了它自己的一致性,整个端到端的一致性级别取决于所有组件中一致性最弱的组件。具体可以划分如下:
- 内部保证:依赖checkpoint
- source 端:需要外部源可重设数据的读取位置
- sink 端:需要保证从故障恢复时,数据不会重复写入外部系统。
而对于sink端,又有两种具体的实现方式: - 幂等(Idempotent)写入:所谓幂等操作,是说一个操作,可以重复执行很多次,但只导致一次结果更改,也就是说,后面再重复执行就不起作用了。
- 事务性(Transactional)写入:需要构建事务来写入外部系统,构建的事务对应着 checkpoint,等到 checkpoint 真正完成的时候,才把所有对应的结果写入 sink 系统中。
对于事务性写入,具体又有两种实现方式:预写日志(WAL)和两阶段提交(2PC)。Flink DataStream API 提供了GenericWriteAheadSink 模板类和 TwoPhaseCommitSinkFunction 接口,可以方便地实现这两种方式的事务性写入。
6.2、Flink+Kafka 实现端到端的 exactly-once语义
端到端的状态一致性的实现,需要每一个组件都实现,对于Flink + Kafka的数据管道系统(Kafka进、Kafka出)而言,各组件怎样保证exactly-once语义呢?
- 内部:利用checkpoint机制,把状态存盘,发生故障的时候可以恢复,保证内部的状态一致性
- source:kafka consumer作为source,可以将偏移量保存下来,如果后续任务出现了故障,恢复的时候可以由连接器重置偏移量,重新消费数据,保证一致性
- sink:kafka producer作为sink,采用两阶段提交 sink,需要实现一个TwoPhaseCommitSinkFunction内部的checkpoint机制。
EXACTLY_ONCE语义简称EOS,指的是每条输入消息只会影响最终结果一次,注意这里是影响一次,而非处理一次,Flink一直宣称自己支持EOS,实际上主要是对于Flink应用内部来说的,对于外部系统(端到端)则有比较强的限制
- 外部系统写入支持幂等性
- 外部系统支持以事务的方式写入
Kafka在0.11版本之前只能保证At-Least-Once或At-Most-Once语义,从0.11版本开始,引入了幂等发送和事务,从而开始保证EXACTLY_ONCE语义。
| Maven依赖 | 开始支持的版本 | 生产/消费 类名 | kafka版本 | 注意 |
|---|---|---|---|---|
| flink-connector-kafka-0.8_2.11 | 1.0.0 | FlinkKafkaConsumer08 FlinkKafkaProducer08 |
0.8.x | 使用Kafka内部SimpleConsumer API. Flink把Offsets提交到ZK |
| flink-connector-kafka-0.9_2.11 | 1.0.0 | FlinkKafkaConsumer09 FlinkKafkaProducer09 |
0.9.x | 使用新版Kafka Consumer API. |
| flink-connector-kafka-0.10_2.11 | 1.2.0 | FlinkKafkaConsumer010 FlinkKafkaProducer010 |
0.10.x | 支持Kafka生产/消费消息带时间戳 |
| flink-connector-kafka-0.11_2.11 | 1.4.0 | FlinkKafkaConsumer011 FlinkKafkaProducer011 |
0.11.x | 由于0.11.x Kafka不支持scala 2.10。此连接器支持Kafka事务消息传递,以便为生产者提供exactly once语义。 |
flink-connector-kafka_2.11 |
1.7.0 | FlinkKafkaConsumer FlinkKafkaProducer |
>=1.0.0 | 高版本向后兼容。但是,对于Kafka 0.11.x和0.10.x版本,我们建议分别使用专用的flink-connector-Kafka-0.11_2.11和link-connector-Kafka-0.10_2.11 |
Flink在1.4.0版本引入了TwoPhaseCommitSinkFunction接口,封装了两阶段提交逻辑,并在Kafka Sink connector中实现了TwoPhaseCommitSinkFunction,依赖Kafka版本为0.11+
public class FlinkKafkaDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment senv = StreamExecutionEnvironment.getExecutionEnvironment();
senv.enableCheckpointing(1000);
senv.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
// kafka 数据源
Map<String, String> config = Configuration.initConfig("commons.xml");
Properties kafkaProps = new Properties();
kafkaProps.setProperty("bootstrap.servers", config.get("kafka-ipport"));
kafkaProps.setProperty("group.id", config.get("kafka-groupid"));
SingleOutputStreamOperator<String> dataStream = senv.addSource(
new FlinkKafkaConsumer011(
config.get("kafka-topic"),
new SimpleStringSchema(),
kafkaProps
));
// sink 到 kafka
FlinkKafkaProducer011<String> producer011 = new FlinkKafkaProducer011<>(
config.get("kafka-ipport"),
"test-kafka-producer",
new SimpleStringSchema());
producer011.setWriteTimestampToKafka(true);
dataStream.map(x -> {
// 抛出异常
if("name4".equals(JSON.parseObject(x).get("name"))){
System.out.println("name4 exception test...");
// throw new RuntimeException("name4 exception test...");
}
return x;
}).addSink(producer011);
senv.execute(FlinkKafkaDemo.class.getSimpleName());
}
}
Flink由JobManager协调各个TaskManager进行checkpoint存储,checkpoint保存在 StateBackend中,默认StateBackend是内存级的,也可以改为文件级的进行持久化保存。
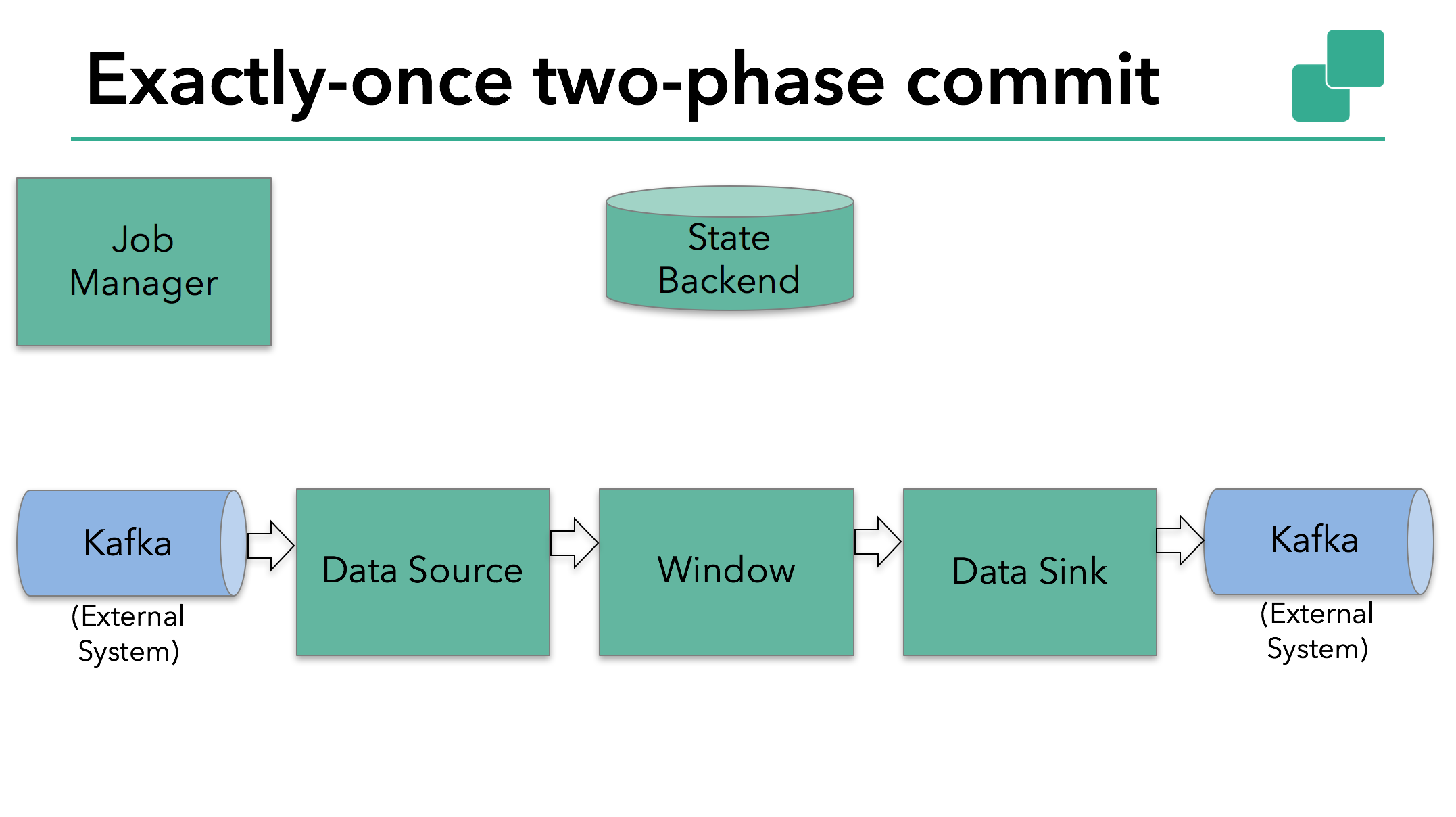
当 checkpoint 启动时,JobManager 会将检查点分界线(barrier)注入数据流;barrier会在算子间传递下去。
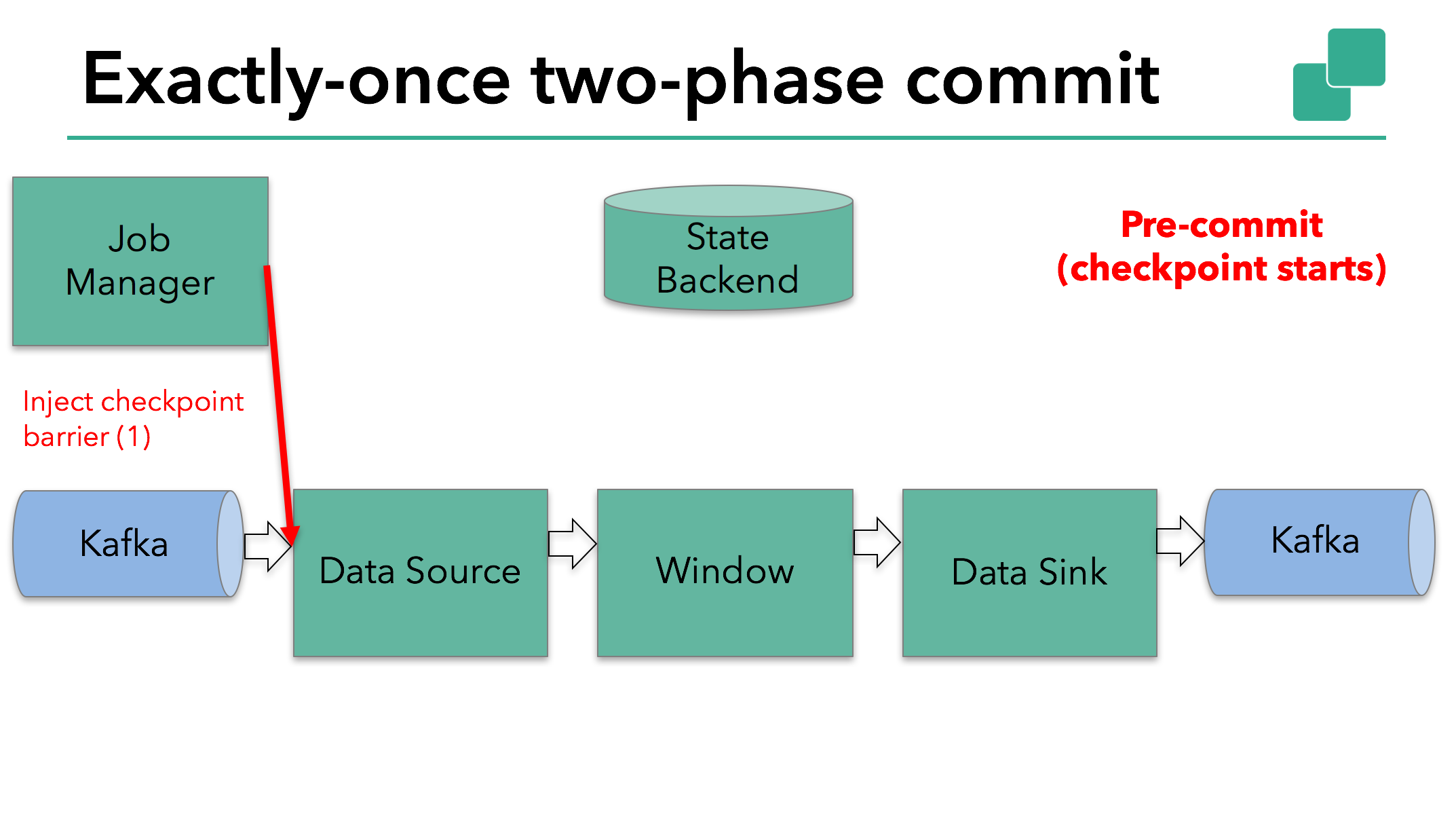
每个算子会对当前的状态做个快照,保存到状态后端。对于source任务而言,就会把当前的offset作为状态保存起来。下次从checkpoint恢复时,source任务可以重新提交偏移量,从上次保存的位置开始重新消费数据。

每个内部的 transform 任务遇到 barrier 时,都会把状态存到 checkpoint 里。
sink 任务首先把数据写入外部 kafka,这些数据都属于预提交的事务(还不能被消费);当遇到 barrier时,把状态保存到状态后端,并开启新的预提交事务。
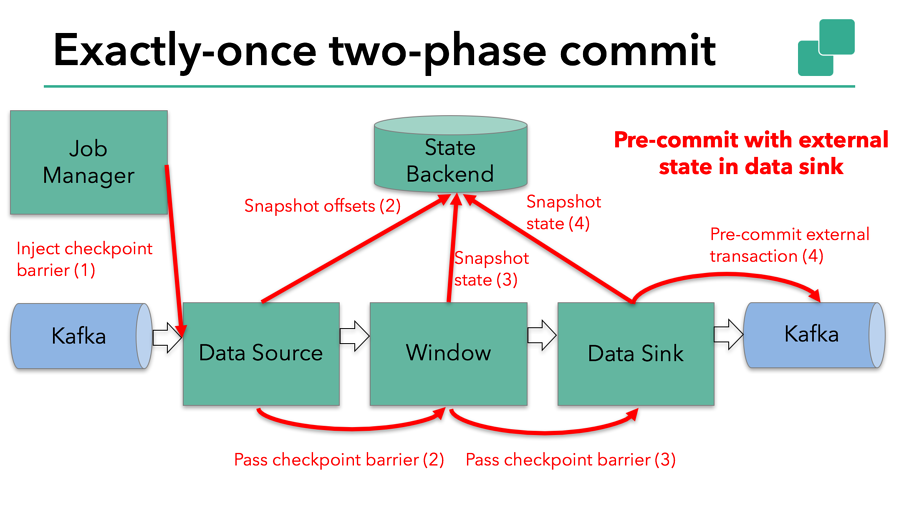
当所有算子任务的快照完成,也就是这次的 checkpoint 完成时,JobManager 会向所有任务发通知,确认这次 checkpoint 完成。当sink 任务收到确认通知,就会正式提交之前的事务,kafka 中未确认的数据就改为“已确认”,数据就真正可以被消费了。
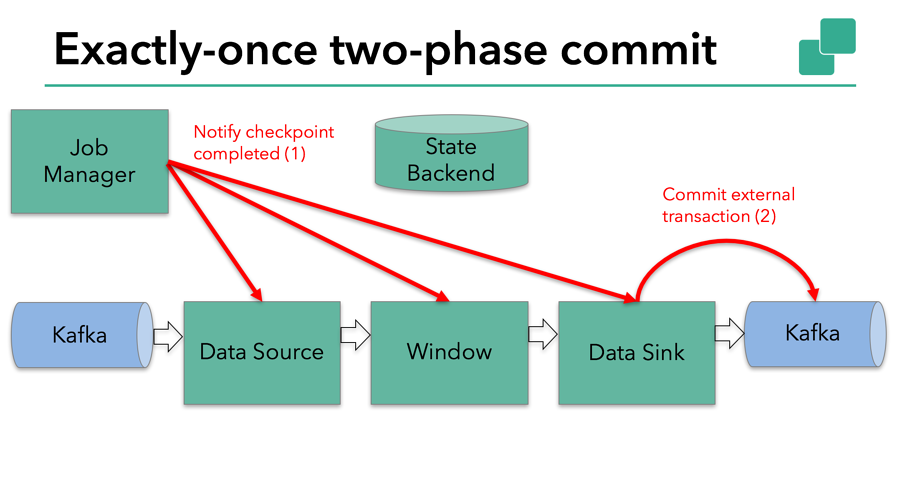
所以看到,执行过程实际上是一个两段式提交,每个算子执行完成,会进行“预提交”,直到执行完sink操作,会发起“确认提交”,如果执行失败,预提交会放弃掉。
具体的两阶段提交步骤总结如下:
- 第一条数据来了之后,开启一个 kafka 的事务(transaction),正常写入 kafka 分区日志但标记为未提交,这就是“预提交”, jobmanager 触发 checkpoint 操作,barrier 从 source 开始向下传递,遇到 barrier 的算子将状态存入状态后端,并通知 jobmanager
- sink 连接器收到 barrier,保存当前状态,存入 checkpoint,通知 jobmanager,并开启下一阶段的事务,用于提交下个检查点的数据
- jobmanager 收到所有任务的通知,发出确认信息,表示 checkpoint 完成
- sink 任务收到 jobmanager 的确认信息,正式提交这段时间的数据
- 外部kafka关闭事务,提交的数据可以正常消费了。
所以也可以看到,如果宕机需要通过StateBackend进行恢复,只能恢复所有确认提交的操作。
6.3、Kafka幂等性和事务
前面表格总结的可以看出,Kafka在0.11版本之前只能保证At-Least-Once或At-Most-Once语义,从0.11版本开始,引入了幂等发送和事务,从而开始保证EXACTLY_ONCE语义。
幂等性
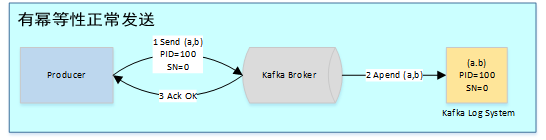
在未引入幂等性时,Kafka正常发送和重试发送消息流程图如下:
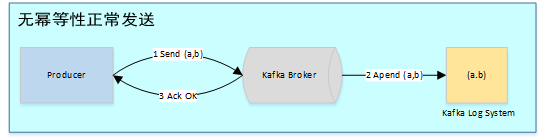
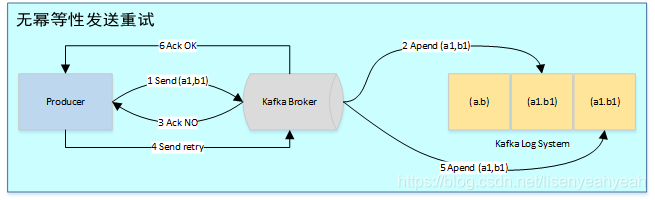
为了实现Producer的幂等语义,Kafka引入了Producer ID(即PID)和Sequence Number。每个新的Producer在初始化的时候会被分配一个唯一的PID,该PID对用户完全透明而不会暴露给用户。
Producer发送每条消息<Topic, Partition>对于Sequence Number会从0开始单调递增,broker端会为每个<PID, Topic, Partition>维护一个序号,每次commit一条消息此序号加一,对于接收的每条消息,如果其序号比Broker维护的序号(即最后一次Commit的消息的序号)大1以上,则Broker会接受它,否则将其丢弃:
- 序号比Broker维护的序号大1以上,说明存在乱序。
- 序号比Broker维护的序号小,说明此消息以及被保存,为重复数据。
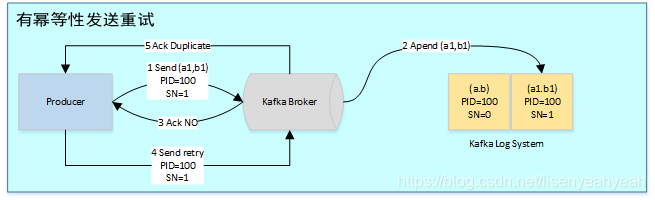
有了幂等性,Kafka正常发送和重试发送消息流程图如下:
事务
事务是指所有的操作作为一个原子,要么都成功,要么都失败,而不会出现部分成功或部分失败的可能。举个例子,比如小明给小王转账1000元,那首先小明的账户会减去1000,然后小王的账户会增加1000,这两个操作就必须作为一个事务,否则就会出现只减不增或只增不减的问题,因此要么都失败,表示此次转账失败。要么都成功,表示此次转账成功。分布式下为了保证事务,一般采用两阶段提交协议。
为了解决跨session和所有分区不能EXACTLY-ONCE问题,Kafka从0.11开始引入了事务。
为了支持事务,Kafka引入了Transacation Coordinator来协调整个事务的进行,并可将事务持久化到内部topic里,类似于offset和group的保存。
用户为应用提供一个全局的Transacation ID,应用重启后Transacation ID不会改变。为了保证新的Producer启动后,旧的具有相同Transaction ID的Producer即失效,每次Producer通过Transaction ID拿到PID的同时,还会获取一个单调递增的epoch。由于旧的Producer的epoch比新Producer的epoch小,Kafka可以很容易识别出该Producer是老的Producer并拒绝其请求。有了Transaction ID后,Kafka可保证:
- 跨Session的数据幂等发送。当具有相同Transaction ID的新的Producer实例被创建且工作时,旧的Producer停止工作。
- 跨Session的事务恢复。如果某个应用实例宕机,新的实例可以保证任何未完成的旧的事务要么Commit要么Abort,使得新实例从一个正常状态开始工作。
KIP-98 对Kafka事务原理进行了详细介绍,完整的流程图如下:
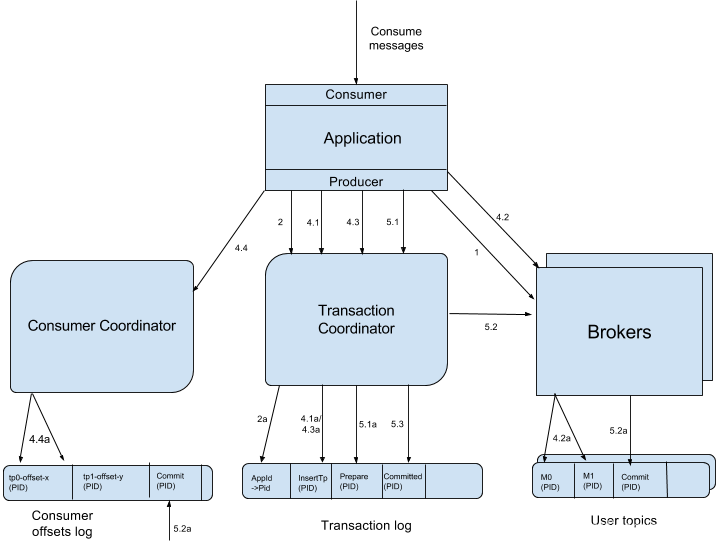
- Producer向任意一个brokers发送 FindCoordinatorRequest请求来获取Transaction Coordinator的地址;
- 找到Transaction Coordinator后,具有幂等特性的Producer必须发起InitPidRequest请求以获取PID。
- 调用beginTransaction()方法开启一个事务,Producer本地会记录已经开启了事务,但Transaction Coordinator只有在Producer发送第一条消息后才认为事务已经开启。
- Consume-Transform-Produce这一阶段,包含了整个事务的数据处理过程,并且包含了多种请求。
- 提交或回滚事务 一旦上述数据写入操作完成,应用程序必须调用KafkaProducer的commitTransaction方法或者abortTransaction方法以结束当前事务。
6.4 两阶段提交协议
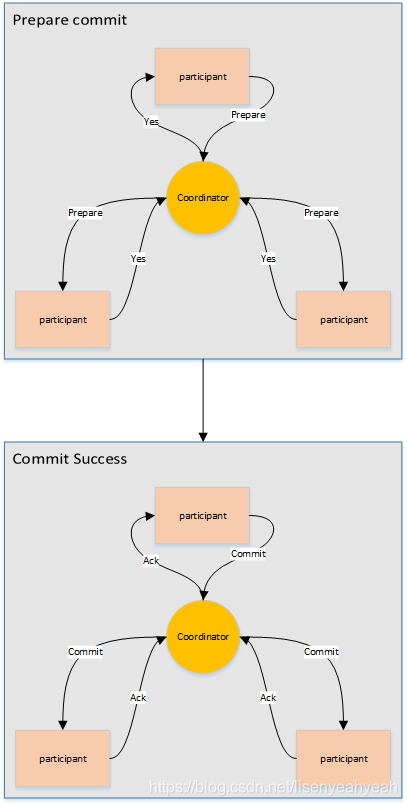
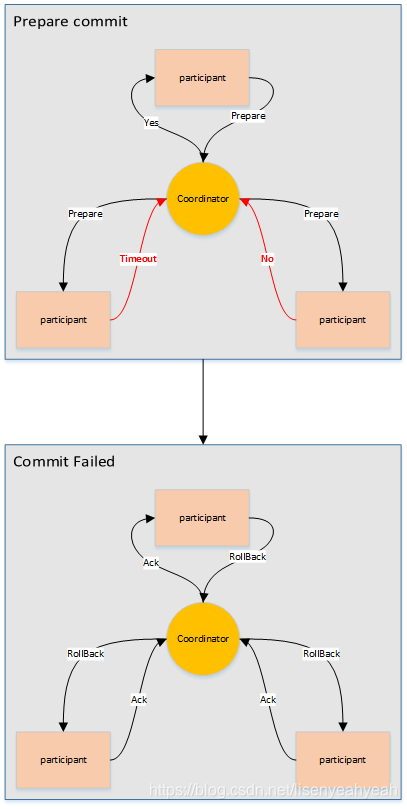
两阶段提交指的是一种协议,经常用来实现分布式事务,可以简单理解为预提交+实际提交,一般分为协调器Coordinator(以下简称C)和若干事务参与者Participant(以下简称P)两种角色。
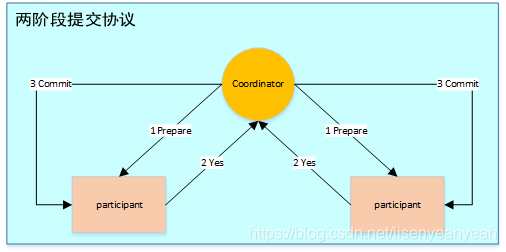
- C先将prepare请求写入本地日志,然后发送一个prepare的请求给P
- P收到prepare请求后,开始执行事务,如果执行成功返回一个Yes或OK状态给C,否则返回No,并将状态存到本地日志。
- C收到P返回的状态,如果每个P的状态都是Yes,则开始执行事务Commit操作,发Commit请求给每个P,P收到Commit请求后各自执行Commit事务操作。如果至少一个P的状态为No,则会执行Abort操作,发Abort请求给每个P,P收到Abort请求后各自执行Abort事务操作。
注:C或P把发送或接收到的消息先写到日志里,主要是为了故障后恢复用,类似WAL
七、链接文档
横向扩展相关来于:Flink状态管理详解:Keyed State和Operator List State深度解析
checkpoint 相关来于:Apache Flink v1.10 官方中文文档




文章评论