

摘要:在本教程中,您将学习如何使用MySQL INNER JOIN子句根据连接条件从多个表中查询数据,以及在使用INNER JOIN的时候如何做到性能最佳。
MySQL INNER JOIN子句
MySQL INNER JOIN子句将一个表中的行与其他表中的行进行匹配,并可以查询这两个表中的字段。
MySQL INNER JOIN子句是SELECT语句的可选部分。它紧接在FROM之后。
在使用MySQL INNER JOIN子句之前,必须指定以下条件:
- 首先,必须指定出现在
FROM子句中的主表。 - 其次,您需要指定要与主表联接的表,该主表出现在
INNER JOIN子句中。理论上,您可以连接具有多个表的表。但是,为了更好的查询性能,您应该限制要加入的表的数量。 - 第三,您需要指定连接条件或连接谓词。连接条件的关键字O
N在INNER JOIN语句之后。连接条件是用于在主表和其他表之间匹配行的条件。
MySQL INNER JOIN子句的语法如下:
SELECT column_list
FROM t1
INNER JOIN t2 ON join_condition1
INNER JOIN t3 ON join_condition2
...
WHERE where_conditions;
INNER JOIN子句连接两个表T1和T2,对于T1表中的每一行,MySQL INNER JOIN子句将它与T2表的每一行进行比较,以检查它们是否都满足连接条件。当连接条件匹配时,它将返回合并两个表T1和T2表中的列的行。
请注意,两个表T1和T2表中的行必须基于连接条件进行匹配。如果未找到匹配项,则查询将返回空结果集。如果我们连接两个以上的表,这个逻辑也适用。
下图说明了MySQL INNER JOIN子句如何工作。结果集中的行必须出现在两个表T1和T2中。
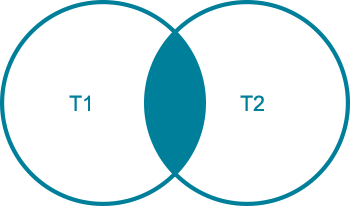
避免在MySQL INNER JOIN中出现歧义错误的列
如果连接多个表,这些表中列名有相同,则在 SELECT 子句中必须使用表限定符指示是对应的列,以避免不明确的列错误。
例如,如果 SELECT 子句中的 T1 和 T2 表都一个列名为 C ,那么必须参考使用表修饰词 T1.C 或 T2.C 指定 C 列(举个例子:高一年级的一班和二班都有一个同学叫小明,年级大会上老师直接喊小明,显然不太适合,应该指明是一班的小明还是二班的小明)。
如果,我是说万一,一个牛逼的数据库管理员创建一个很长很长的表名称为:there-are-veryvery-longtable-name,为了节省输入表名称的时间,您可以在查询中使用表的别名。例如,可以给 there-are-veryvery-longtable-name 表一个别名为 T ,并指它的列 T.column 代替 there-are-veryvery-longtable-name.column。
MySQL INNER JOIN子句示例
让我们来看看示例数据库中的products和productlines表。
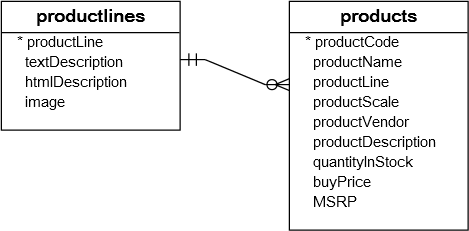
现在,如果你想得到
- 从 product 表中读取产品代码(
product_code字段)和产品名称(product_name字段); - 从 category 表中读取分类名称(name字段)
那么我们需要从 product 表中的 category_id 字段,以及 category 表的 category_id 字段进行比较,并选择两个表相匹配的行记录:
SELECT
productCode,
productName,
textDescription
FROM
products T1
INNER JOIN productlines T2 ON T1.productline = T2.productline;
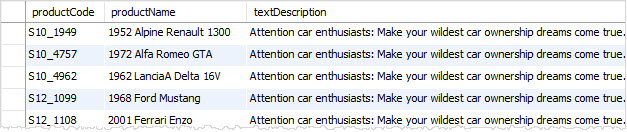
结果如下:
MySQL INNER JOIN与GROUP BY子句
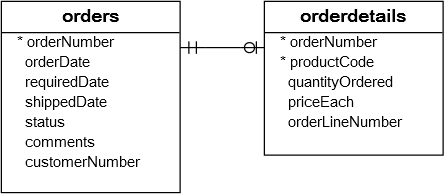
请参阅以下orders和orderdetails表。
我们可以使用 INNER JOIN 子句与 GROUP BY子句及从 order 表和 order_detail 表是查询得到订单号,订单状态和总销量:
SELECT
T1.orderNumber,
STATUS,
SUM(quantityOrdered * priceEach) total
FROM
orders AS T1
INNER JOIN orderdetails AS T2 ON T1.orderNumber = T2.orderNumber
GROUP BY
orderNumber;
结果如图所示:
MySQL INNER JOIN优化及效率
假定我们有一个如下形式的表T1、T2、T3的联接查询:
SELECT * FROM T1 INNER JOIN T2 ON P1(T1,T2)
INNER JOIN T3 ON P2(T2,T3)
WHERE P(T1,T2,T3).
这里,P1(T1,T2)和P2(T3,T3)是一些联接条件(表达式),其中P(t1,t2,t3)是表T1、T2、T3的列的一个条件。
嵌套环联接算法将按下面的方式执行该查询:
FOR each row t1 in T1 {
FOR each row t2 in T2 such that P1(t1,t2) {
FOR each row t3 in T3 such that P2(t2,t3) {
IF P(t1,t2,t3) {
t:=t1||t2||t3; OUTPUT t;
}
}
}
}
符号t1||t2||t3表示“连接行t1、t2和t3的列组成的行”。
其实我觉得,完全可以把P(t1, t2, t3)拆到进入循环前就处理,像这样(后来仔细看了文档,MySQL在内联接的时候还是会优化成这样的):
FOR each row t1 in T1 {
IF P(t1) {
FOR each row t2 in T2 such that P1(t1,t2) {
IF P(t2) {
FOR each row t3 in T3 such that P2(t2,t3) {
IF P(t3) {
t:=t1||t2||t3; OUTPUT t;
}
}
}
}
}
}
甚至更快的是把条件全部合并起来:
FOR each row t1 in T1 {
IF P(t1) {
FOR each row t2 in T2 such that (P1(t1,t2) && P(t2)) {
FOR each row t3 in T3 such that (P2(t2,t3) && P(t3)) {
t:=t1||t2||t3; OUTPUT t;
}
}
}
}
我写了个程序,把方法一(MySQL的方法)和方法三的效率进行比较,明显方法三要高。
#include
#include
#include
#define MAXN 100000
using namespace std;
int a[MAXN];
int b[MAXN];
int c[MAXN];
int count = 0;
int main() {
clock_t start, finish;
double time1, time2;
count = 0;
srand(time(0));
for(int i=0; i500 and b[j] < 800 and c[k]>120) {
cout << ++count << ':' <500) {
for(int j=10; j120) {
cout << ++count << ':' <
我跑的结果是,一共输出292条记录,21.82s VS 8.35s。 可见先做条件判断是很能提高效率的。
在本教程中,您已经学习了如何使用MySQL INNER JOIN从多个表中查询数据。您还学习了如何使用表限定符避免在MySQL INNER JOIN子句中的歧义列错误, 以及MySQL INNER JOIN效率分析实例。




文章评论