

1、请简述Zookeeper的选举机制
假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。
假设这些服务器依序启动,来看看会发生什么。
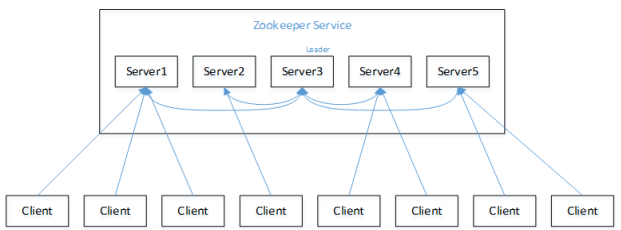
(1)服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态。
(2)服务器2启动,它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,所以id值较大的服务器2胜出,
但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态。
(3)服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的Leader,而与上面不同的是,此时有三台服务器选举了它,
所以它成为了这次选举的Leader。
(4)服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,
所以它成为Follower。
(5)服务器5启动,同4一样成为Follower。
注意,如果按照5,4,3,2,1的顺序启动,那么5将成为Leader,因为在满足半数条件后,ZooKeeper集群启动,5的Id最大,被选举为Leader。
2、客户端如何正确处理CONNECTIONLOSS(连接断开) 和 SESSIONEXPIRED(Session 过期)两类连接异常?
在ZooKeeper中,服务器和客户端之间维持的是一个长连接,在 SESSION_TIMEOUT 时间内,服务器会确定客户端是否正常连接(客户端会定时向服务器发送
heart_beat),服务器重置下次SESSION_TIMEOUT时间。因此,在正常情况下,Session一直有效,并且zk集群所有机器上都保存这个Session信息。在出现问题的情况下,
客户端与服务器之间连接断了(客户端所连接的那台zk机器挂了,或是其它原因的网络闪断),这个时候客户端会主动在地址列表(初始化的时候传入构造方法的那个
参数connectString)中选择新的地址进行连接。
以上即为服务器与客户端之间维持长连接的过程,在这个过程中,用户可能会看到两类异常CONNECTIONLOSS(连接断开) 和SESSIONEXPIRED(Session 过期)。
发生CONNECTIONLOSS后,此时用户不需要关心我的会话是否可用,应用所要做的就是等待客户端帮我们自动连接上新的zk机器,一旦成功连接上新的zk机器后,
确认之前的操作是否执行成功了。
3、一个客户端修改了某个节点的数据,其他客户端能够马上获取到这个最新数据吗?
ZooKeeper不能确保任何客户端能够获取(即Read Request)到一样的数据,除非客户端自己要求,方法是客户端在获取数据之前调用
org.apache.zookeeper.AsyncCallbac k.VoidCallback, java.lang.Object) sync。
通常情况下(这里所说的通常情况满足:1. 对获取的数据是否是最新版本不敏感,2. 一个客户端修改了数据,其它客户端是否需要立即能够获取最新数据),
可以不关心这点。
在其它情况下,最清晰的场景是这样:ZK客户端A对 /my_test 的内容从 v1->v2, 但是ZK客户端B对 /my_test 的内容获取,依然得到的是 v1. 请注意,
这个是实际存在的现象,当然延时很短。解决的方法是客户端B先调用 sync(), 再调用 getData()。
4、ZooKeeper对节点的watch监听是永久的吗?为什么?
不是。
官方声明:一个Watch事件是一个一次性的触发器,当被设置了Watch的数据发生了改变的时候,则服务器将这个改变发送给设置了Watch的客户端,
以便通知它们。
为什么不是永久的,举个例子,如果服务端变动频繁,而监听的客户端很多情况下,每次变动都要通知到所有的客户端,这太消耗性能了。
一般是客户端执行getData(“/节点A”,true),如果节点A发生了变更或删除,客户端会得到它的watch事件,但是在之后节点A又发生了变更,
而客户端又没有设置watch事件,就不再给客户端发送。
在实际应用中,很多情况下,我们的客户端不需要知道服务端的每一次变动,我只要最新的数据即可。
5、ZooKeeper中使用watch的注意事项有哪些?
使用watch需要注意的几点:
1)Watches通知是一次性的,必须重复注册。
2)发生CONNECTIONLOSS之后,只要在session_timeout之内再次连接上(即不发生SESSIONEXPIRED),那么这个连接注册的watches依然在。
3)节点数据的版本变化会触发NodeDataChanged,注意,这里特意说明了是版本变化。存在这样的情况,只要成功执行了setData()方法,
无论内容是否和之前一致,都会触发NodeDataChanged。
4)对某个节点注册了watch,但是节点被删除了,那么注册在这个节点上的watches都会被移除。
5)同一个zk客户端对某一个节点注册相同的watch,只会收到一次通知。
6)Watcher对象只会保存在客户端,不会传递到服务端。
6、能否收到每次节点变化的通知?
如果节点数据的更新频率很高的话,不能。
原因在于:当一次数据修改,通知客户端,客户端再次注册watch,在这个过程中,可能数据已经发生了许多次数据修改,因此,
千万不要做这样的测试:”数据被修改了n次,一定会收到n次通知”来测试server是否正常工作。
7、能否为临时节点创建子节点?
ZooKeeper中不能为临时节点创建子节点,如果需要创建子节点,应该将要创建子节点的节点创建为永久性节点。
8、是否可以拒绝单个IP对ZooKeeper的访问?
如何实现?ZK本身不提供这样的功能,它仅仅提供了对单个IP的连接数的限制。你可以通过修改iptables来实现对单个ip的限制。
9、创建的临时节点什么时候会被删除,是连接一断就删除吗?
延时是多少?连接断了之后,ZK不会马上移除临时数据,只有当SESSIONEXPIRED之后,才会把这个会话建立的临时数据移除。因此,
用户需要谨慎设置Session_TimeOut。
10、ZooKeeper是否支持动态进行机器扩容?如果目前不支持,那么要如何扩容呢?
ZooKeeper中的动态扩容其实就是水平扩容,Zookeeper对这方面的支持不太好,目前有两种方式:
全部重启:关闭所有Zookeeper服务,修改配置之后启动,不影响之前客户端的会话。
逐个重启:这是比较常用的方式。
11、ZooKeeper集群中服务器之间是怎样通信的?
Leader服务器会和每一个Follower/Observer服务器都建立TCP连接,同时为每个F/O都创建一个叫做LearnerHandler的实体。
LearnerHandler主要负责Leader和F/O之间的网络通讯,包括数据同步,请求转发和Proposal提议的投票等。Leader服务器保存了所有F/O的LearnerHandler。
12、ZooKeeper是否会自动进行日志清理?
如何进行日志清理?zk自己不会进行日志清理,需要运维人员进行日志清理。
13、谈谈你对ZooKeeper的理解?
Zookeeper 作为一个分布式的服务框架,主要用来解决分布式集群中应用系统的一致性问题。ZooKeeper提供的服务包括:分布式消息同步和协调机制、
服务器节点动态上下线、统一配置管理、负载均衡、集群管理等。
ZooKeeper提供基于类似于Linux文件系统的目录节点树方式的数据存储,即分层命名空间。Zookeeper 并不是用来专门存储数据的,
它的作用主要是用来维护和监控你存储的数据的状态变化,通过监控这些数据状态的变化,从而可以达到基于数据的集群管理,ZooKeeper节点的数据上限是1MB。
我们可以认为Zookeeper=文件系统+通知机制,对于ZooKeeper的数据结构,每个子目录项如 NameService 都被称作为 znode,这个 znode 是被它所在的
路径唯一标识,如 Server1 这个 znode 的标识为 /NameService/Server1;
znode 可以有子节点目录,并且每个 znode 可以存储数据,注意 EPHEMERAL 类型的目录节点不能有子节点目录(因为它是临时节点);
znode 是有版本的,每个 znode 中存储的数据可以有多个版本,也就是一个访问路径中可以存储多份数据;
znode 可以是临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除,Zookeeper 的客户端和服务器通信采用长连接方式,
每个客户端和服务器通过心跳来保持连接,这个连接状态称为 session,如果 znode 是临时节点,这个 session 失效,znode 也就删除了;
znode 的目录名可以自动编号,如 App1 已经存在,再创建的话,将会自动命名为 App2;
znode 可以被监控,包括这个目录节点中存储的数据的修改,子节点目录的变化等,一旦变化可以通知设置监控的客户端,这个是 Zookeeper 的核心特性,
Zookeeper 的很多功能都是基于这个特性实现的,后面在典型的应用场景中会有实例介绍。
14、ZooKeeper节点类型?
1)Znode有两种类型:
短暂(ephemeral):客户端和服务器端断开连接后,创建的节点自己删除。
持久(persistent):客户端和服务器端断开连接后,创建的节点不删除。
2)Znode有四种形式的目录节点(默认是persistent )
(1)持久化目录节点(PERSISTENT) 客户端与zookeeper断开连接后,该节点依旧存在。
(2)持久化顺序编号目录节点(PERSISTENT_SEQUENTIAL) 客户端与zookeeper断开连接后,该节点依旧存在,
只是Zookeeper给该节点名称进行顺序编号。
(3)临时目录节点(EPHEMERAL) 客户端与zookeeper断开连接后,该节点被删除。
(4)临时顺序编号目录节点(EPHEMERAL_SEQUENTIAL)客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号。
15、请说明ZooKeeper的通知机制?
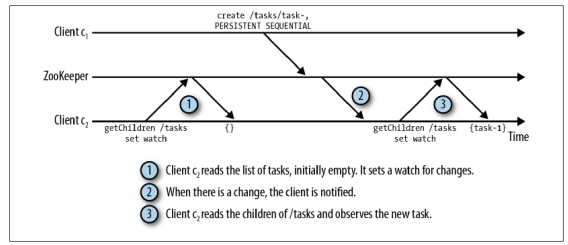
ZooKeeper选择了基于通知(notification)的机制,即:客户端向ZooKeeper注册需要接受通知的znode,通过znode设置监控点(watch)来接受通知。
监视点是一个单次触发的操作,意即监视点会触发一个通知。为了接收多个通知,客户端必须在每次通知后设置一个新的监视点。在下图阐述的情况下,
当节点/task发生变化时,客户端会受到一个通知,并从ZooKeeper读取一个新值。
16、ZooKeeper的监听原理是什么?
在应用程序中,mian()方法首先会创建zkClient,创建zkClient的同时就会产生两个进程,即Listener进程(监听进程)和
connect进程(网络连接/传输进程),当zkClient调用getChildren()等方法注册监视器时,connect进程向ZooKeeper注册监听器,
注册后的监听器位于ZooKeeper的监听器列表中,监听器列表中记录了zkClient的IP,端口号以及要监控的路径,一旦目标文件发生变化,
ZooKeeper就会把这条消息发送给对应的zkClient的Listener()进程,Listener进程接收到后,就会执行process()方法,
在process()方法中针对发生的事件进行处理。

17、请说明ZooKeeper使用到的各个端口的作用?
2888:Follower与Leader交换信息的端口。
3888:万一集群中的Leader服务器挂了,需要一个端口来重新进行选举,选出一个新的Leader,而这个端口就是用来执行选举时服务器相互通信的端口。
18、ZooKeeper的部署方式有哪几种?集群中的角色有哪些?集群最少需要几台机器?
ZooKeeper的部署方式有单机模式和集群模式,集群中的角色有Leader和Follower,集群最少3(2N+1)台,根据选举算法,应保证奇数。
19、ZooKeeper集群如果有3台机器,挂掉一台是否还能工作?挂掉两台呢?
对于ZooKeeper集群,过半存活即可使用。
20、ZooKeeper使用的ZAB协议与Paxo算法的异同?
Paxos算法是分布式选举算法,Zookeeper使用的 ZAB协议(Zookeeper原子广播),两者的异同如下:
1)相同之处:
比如都有一个Leader,用来协调N个Follower的运行;Leader要等待超半数的Follower做出正确反馈之后才进行提案;
二者都有一个值来代表Leader的周期。
2)不同之处:
ZAB用来构建高可用的分布式数据主备系统(Zookeeper),Paxos是用来构建分布式一致性状态机系统。
21、请谈谈对ZooKeeper对事务性的支持?
ZooKeeper对于事务性的支持主要依赖于四个函数,zoo_create_op_init, zoo_delete_op_init, zoo_set_op_init以及zoo_check_op_init。
每一个函数都会在客户端初始化一个operation,客户端程序有义务保留这些operations。当准备好一个事务中的所有操作后,可以使用zoo_multi来提交所有的操作,
由zookeeper服务来保证这一系列操作的原子性。也就是说只要其中有一个操作失败了,相当于此次提交的任何一个操作都没有对服务端的数据造成影响。
Zoo_multi的返回值是第一个失败操作的状态信号。




文章评论