
Hive系列文章
- Hive表的基本操作
- Hive中的集合数据类型
- Hive动态分区详解
- hive中orc格式表的数据导入
- Java通过jdbc连接hive
- 通过HiveServer2访问Hive
- SpringBoot连接Hive实现自助取数
- hive关联hbase表
- Hive udf 使用方法
- Hive基于UDF进行文本分词
- Hive窗口函数row number的用法
- 数据仓库之拉链表
先解释一下几个名词:
- metadata :hive元数据,即hive定义的表名,字段名,类型,分区,用户这些数据。一般存储关系型书库mysql中,在测试阶段也可以用hive内置Derby数据库。
- metastore :hivestore服务端。主要提供将DDL,DML等语句转换为MapReduce,提交到hdfs中。
- hiveserver2:hive服务端。提供hive服务。客户端可以通过beeline,jdbc(即用java代码链接)等多种方式链接到hive。
- beeline:hive客户端链接到hive的一个工具。可以理解成mysql的客户端。如:navite cat 等。
其它语言访问hive主要是通过hiveserver2服务,HiveServer2(HS2)是一种能使客户端执行Hive查询的服务。HiveServer2可以支持对 HiveServer2 的嵌入式和远程访问,支持多客户端并发和身份认证。旨在为开放API客户端(如JDBC和ODBC)提供更好的支持。
会启动一个hive服务端默认端口为:10000,可以通过beeline,jdbc,odbc的方式链接到hive。hiveserver2启动的时候会先检查有没有配置hive.metastore.uris,如果没有会先启动一个metastore服务,然后在启动hiveserver2。如果有配置hive.metastore.uris。会连接到远程的metastore服务。这种方式是最常用的。部署在图如下: 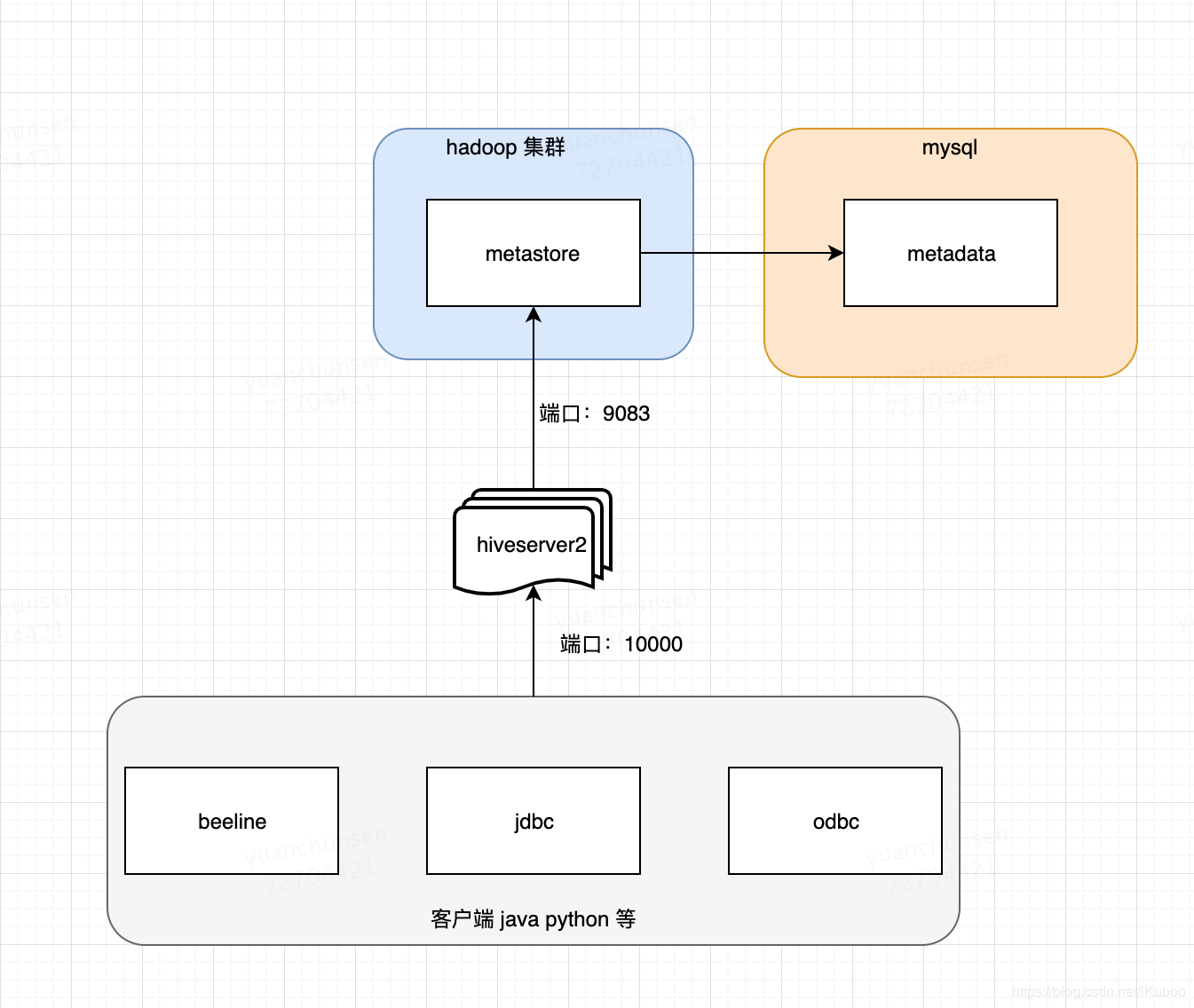
Python连接Hive
Python3访问hive需要安装的依赖有:
- pip3 install thrift
- pip3 install PyHive
- pip3 install sasl
- pip3 install thrift_sasl
这里有一个Python访问Hive的工具类:
# -*- coding:utf-8 -*-
from pyhive import hive
class HiveClient(object):
"""docstring for HiveClient"""
def __init__(self, host='hadoop-master',port=10000,username='hadoop',password='hadoop',database='hadoop',auth='LDAP'):
"""
create connection to hive server2
"""
self.conn = hive.Connection(host=host,
port=port,
username=username,
password=password,
database=database,
auth=auth)
def query(self, sql):
"""
query
"""
with self.conn.cursor() as cursor:
cursor.execute(sql)
return cursor.fetchall()
def insert(self, sql):
"""
insert action
"""
with self.conn.cursor() as cursor:
cursor.execute(sql)
# self.conn.commit()
# self.conn.rollback()
def close(self):
"""
close connection
"""
self.conn.close()使用的时候,只需要导入,然后创建一个对象实例即可,传入sql调用query方法完成查询。
# 拿一个连接
hclient = hive.HiveClient()
# 执行查询操作
...
# 关闭连接
hclient.close()注意:在insert插入方法中,我将self.conn.commit()和self.conn.rollback()即回滚注释了,这是传统关系型数据库才有的事务操作,Hive中是不支持的。
Java连接Hive
Java作为大数据的基础语言,连接hive自然是支持的很好的,这里介绍通过jdbc和mybatis两种方法连接hive。
1. Jdbc连接
java通过jdbc连接hiveserver,跟传统的jdbc连接mysql方法一样。
需要hive-jdbc依赖:
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>1.2.1</version>
</dependency>代码跟连接mysql套路一样,都是使用的DriverManager.getConnection(url, username, password):
@NoArgsConstructor
@AllArgsConstructor
@Data
@ToString
public class HiveConfigModel {
private String url = "jdbc:hive2://localhost:10000";
private String username = "hadoop";
private String password = "hadoop";
}
@Test
public void test(){
// 初始化配置
HiveConfigModel hiveConfigModel = ConfigureContext.getInstance("hive-config.properties")
.addClass(HiveConfigModel.class)
.getModelProperties(HiveConfigModel.class);
try {
Connection conn = DriverManager.getConnection(hiveConfigModel.getUrl(),
hiveConfigModel.getUsername(), hiveConfigModel.getPassword());
String sql = "show tables";
PreparedStatement preparedStatement = conn.prepareStatement(sql);
ResultSet rs = preparedStatement.executeQuery();
List<String> tables = new ArrayList<>();
while (rs.next()){
tables.add(rs.getString(1));
}
System.out.println(tables);
} catch (SQLException e) {
e.printStackTrace();
}
}在hive-jdbc-1.2.1.jar的META-INF下有个services目录,里面有个java.sql.Driver文件,内容是:
org.apache.hive.jdbc.HiveDriverjava.sql.DriverManager使用spi实现了服务接口与服务实现分离以达到解耦,在这里jdbc的实现org.apache.hive.jdbc.HiveDriver根据java.sql.Driver提供的统一规范实现逻辑。客户端使用jdbc时不需要去改变代码,直接引入不同的spi接口服务即可。
DriverManager.getConnection(url, username, password)这样即可拿到连接,前提是具体实现需要遵循相应的spi规范。
2. 整合mybatis
通常都会使用mybatis来做dao层访问数据库,访问hive也是类似的。
配置文件sqlConfig.xml:
<?xml version="1.0" encoding="UTF-8" ?>
<configuration>
<environments default="production">
<environment id="production">
<transactionManager type="JDBC"/>
<dataSource type="POOLED">
<property name="driver" value="org.apache.hive.jdbc.HiveDriver"/>
<property name="url" value="jdbc:hive2://master:10000/default"/>
<property name="username" value="hadoop"/>
<property name="password" value="hadoop"/>
</dataSource>
</environment>
</environments>
<mappers>
<mapper resource="mapper/hive/test/test.xml"/>
</mappers>
</configuration>mapper代码省略,实现代码:
public classTestMapperImpl implements TestMapper {
private static SqlSessionFactory sqlSessionFactory = HiveSqlSessionFactory.getInstance().getSqlSessionFactory();
@Override
public int getTestCount(String dateTime) {
SqlSession sqlSession = sqlSessionFactory.openSession();
TestMapper testMapper = sqlSession.getMapper(TestMapper.class);
int count = testMapper.getTestCount(dateTime);
sqlSession.close();
return count;
}
}



文章评论