
explode 和 lateral view
为什么把这两个放一块呢,因为这两个经常放在一起用啊。
explode与lateral view在关系型数据库中本身是不该出现的,因为他的出现本身就是在操作不满足第一范式的数据(每个属性都不可再分),本身已经违背了数据库的设计原理(不论是业务系统还是数据仓库系统),不过大数据技术普及后,很多类似pv,uv的数据,在业务系统中是存贮在非关系型数据库中,用json存储的概率比较大,直接导入hive为基础的数仓系统中,就需要经过ETL过程解析这类数据,explode与lateral view在这种场景下大显身手。
explode用法
在介绍如何处理之前,我们先来了解下Hive内置的 explode 函数,官方的解释是:explode() takes in an array (or a map) as an input and outputs the elements of the array (map) as separate rows. UDTFs can be used in the SELECT expression list and as a part of LATERAL VIEW. 意思就是 explode() 接收一个 array 或 map 类型的数据作为输入,然后将 array 或 map 里面的元素按照每行的形式输出。其可以配合 LATERAL VIEW 一起使用。光看文字描述很不直观,咱们来看看几个例子吧。
hive (default)> select explode(array('A','B','C'));
OK
A
B
C
Time taken: 4.188 seconds, Fetched: 3 row(s)
hive (default)> select explode(map('a', 1, 'b', 2, 'c', 3));
OK
key value
a 1
b 2
c 3 explode函数接收一个数组或者map类型的数据,通常需要用split函数生成数组。
explode 配合解析Json 数组
这里有数据:
{"info":[
{"AppName":"SogouExplorer_embedupdate","pepper":"-1"},
{"AppName":"SogouExplorer_embedupdate","pepper":"-1"},
{"AppName":"SogouExplorer_embedupdate","pepper":"-1"},
{"AppName":"2345Explorer_embedupdate","plugin":"-1"},
{"AppName":"SogouExplorer_embedupdate","pepper":"-1"}
]}现在需要将AppName和pepper提取出来,然后按行存放,一行一个,首先我们按照上一节我们学习的Json 处理的函数进行尝试
select
get_json_object(
'{"info":[
{"AppName":"SogouExplorer_embedupdate","pepper":"-1"},
{"AppName":"SogouExplorer_embedupdate","pepper":"-1"},
{"AppName":"SogouExplorer_embedupdate","pepper":"-1"},
{"AppName":"2345Explorer_embedupdate","plugin":"-1"},
{"AppName":"SogouExplorer_embedupdate","pepper":"-1"}
]}',
"$.info[*].AppName"
);如图 
但是我们注意到这里虽然提取出来了但是返回值是一个字符串啊,我为啥知道它是字符串,但是看起来像是一个数组啊,因为我用explode 函数试过了,那接下来怎么处理呢,这个时候就可以需要配合split 处理了,为了方便操作我直接用上么的结果进行操作
["SogouExplorer_embedupdate","SogouExplorer_embedupdate","SogouExplorer_embedupdate","2345Explorer_embedupdate","SogouExplorer_embedupdate"]然我我们尝试处理一下上面这个字符串,首先我们需要split 一下,但是在此之前我们需要将两边的中括号去掉,否则到时候我们的数据会包含这个两个符号的
select regexp_replace('["SogouExplorer_embedupdate","SogouExplorer_embedupdate","SogouExplorer_embedupdate","2345Explorer_embedupdate","SogouExplorer_embedupdate"]',"[\\[\\]]",'')然后我们就可以split和explode 的了
select explode(split(regexp_replace('["SogouExplorer_embedupdate","SogouExplorer_embedupdate","SogouExplorer_embedupdate","2345Explorer_embedupdate","SogouExplorer_embedupdate"]',"[\\[\\]]",''),','));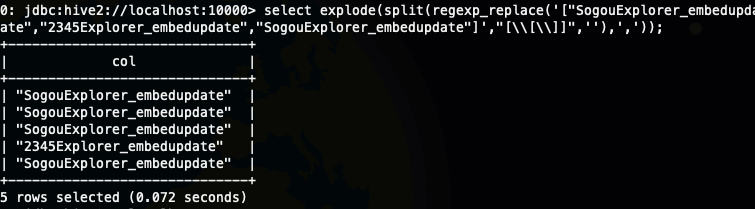
这里解析json数组,我们本质上还是使用regexp_replace替换掉中括号,然后再使用split函数拆分为数据,给explode去分裂成多行。上面的这种写法有问题吗,功能是可以完成,但是这里只是提出来了AppName 这个字段,还有一个字段没有提取出来呢,要是想把它提取出来,上面的步骤你还得再来一遍才可以,接下来我们尝试引入json_tuple来简化一下我们的操作,我们先将其explode 成多行简单json 字符串,然后再使用json_tuple 进行处理
select
explode(
split(
regexp_replace(
regexp_replace(
get_json_object(
'{"info":[
{"AppName":"SogouExplorer_embedupdate","pepper":"-1"},
{"AppName":"SogouExplorer_embedupdate","pepper":"-1"},
{"AppName":"SogouExplorer_embedupdate","pepper":"-1"},
{"AppName":"2345Explorer_embedupdate","plugin":"-1"},
{"AppName":"SogouExplorer_embedupdate","pepper":"-1"}
]}',"$.info")
,'[\\[\\]]' ,'')
,'(},\\{)','}#\\{')
,'#')
);这里两次调用了regexp_replace,第一次是为了去掉两边的中括号,第二次是为了将,jons 里面的逗号和分割json 的逗号进行区分,因为我们按照数组内容之间的分隔符进行split ,所以这里可以看做是将数组字符串的分隔符有逗号换成了# 号,然后就按照# split 了
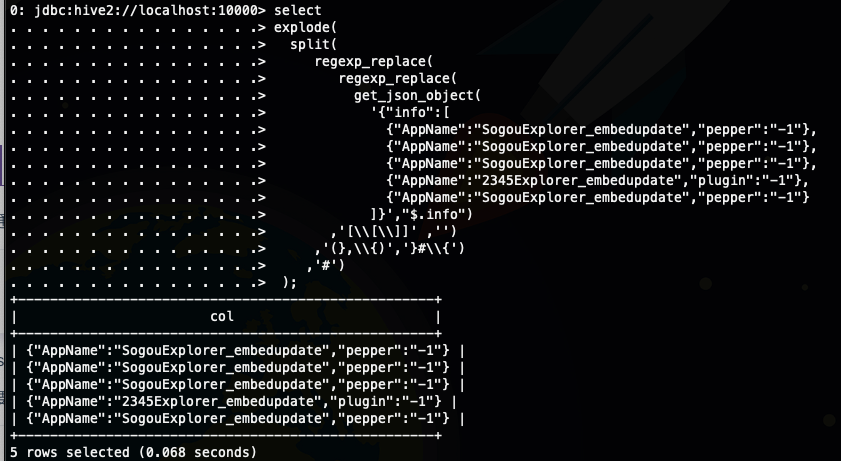
接下来就可以调用json_tuple 函数了
select
json_tuple(data,'AppName','pepper')
from(
select
explode(
split(
regexp_replace(
regexp_replace(
get_json_object(
'{"info":[
{"AppName":"SogouExplorer_embedupdate","pepper":"-1"},
{"AppName":"SogouExplorer_embedupdate","pepper":"-1"},
{"AppName":"SogouExplorer_embedupdate","pepper":"-1"},
{"AppName":"2345Explorer_embedupdate","plugin":"-1"},
{"AppName":"SogouExplorer_embedupdate","pepper":"-1"}
]}',"$.info")
,'[\\[\\]]' ,'')
,'(},\\{)','}#\\{')
,'#')
) as data
) json_table;如图 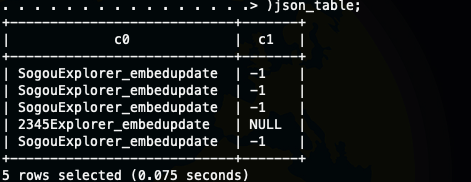
这样我们就将我们需要的字段解析出来了
lateral view
开始之前我们先说一下它的用法 LATERAL VIEW udtf(expression) tableAlias AS columnAlias ,你可以将lateral view翻译为侧视图
我们有这样的一份样本数据(
刘德华 演员,导演,制片人
李小龙 演员,导演,制片人,幕后,武术指导
李连杰 演员,武术指导
刘亦菲 演员这里我们希望转换成下面这样的格式
刘德华 演员
刘德华 导演
刘德华 制片人
李小龙 演员
李小龙 导演
李小龙 制片人
李小龙 幕后
李小龙 武术指导create table ods.ods_actor_data(
username string,
userrole string
)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '\t';
load data local inpath "/Users/liuwenqiang/workspace/hive/lateral.data" overwrite into table ods.ods_actor_data;如图 
从我们前面的学习,我们知道这里应该用explode函数
select explode(split(userrole,',')) from ods.ods_actor_data;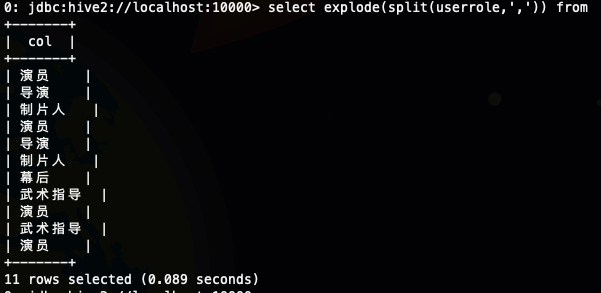
理论上我们这下只要把username 也选出来就可以了
select username,explode(split(userrole,',')) from ods.ods_actor_data;Error: Error while compiling statement: FAILED: SemanticException [Error 10081]: UDTF's are not supported outside the SELECT clause, nor nested in expressions (state=42000,code=10081)
因为explode 是一个UDTF,所以你不能直接和其他字段一起使用,那应该怎么做呢在
select
username,role
from
ods.ods_actor_data
LATERAL VIEW
explode(split(userrole,',')) tmpTable as role
;如图 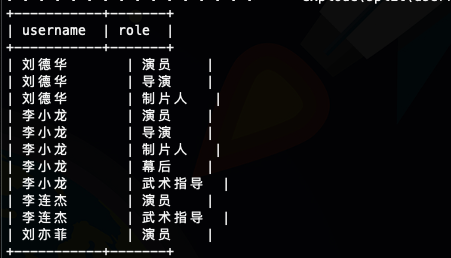
看起来到这里我们的实现就结束了
lateral view outer
为什么会多了一个 OUTER 关键字呢,其实你也可以猜到了outer join 有点像,就是为了避免explode 函数返回值是null 的时候,影响我们主表的返回,注意是null 而不是空字符串
select
username,role
from
ods.ods_actor_data
LATERAL VIEW
explode(array()) tmpTable as role
;如图 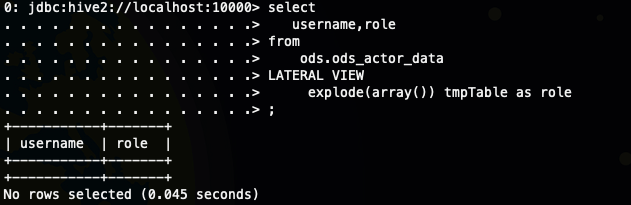
加上outer 关键字之后
select
username,role
from
ods.ods_actor_data
LATERAL VIEW outer
explode(array()) tmpTable as role
;如图 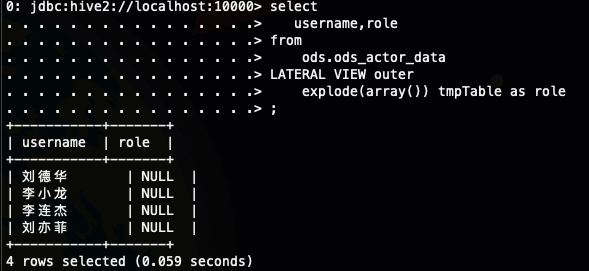
其实一个SQL你可以多次使用lateral view也是可以的,就像下面这样
SELECT * FROM exampleTable
LATERAL VIEW explode(col1) myTable1 AS myCol1
LATERAL VIEW explode(myCol1) myTable2 AS myCol2;lateral view 的实现原理是什么
首先我们知道explode()是一个UDTF 就是一个输入进去,多个输出出来,或者是进去一行,出来一列(多行)
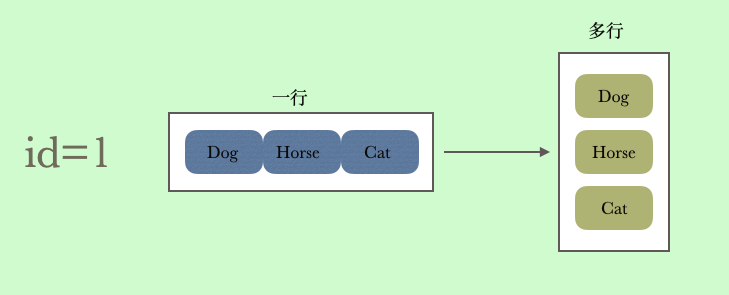
lateral view 关键字就是将每一行的特定字段交给explode 函数的表达式,然后将输出结果和当前行做笛卡尔积,然后重复,直到循环完表里的全部数据,然后就变成下面装了(图中省略了传给explode 字段的那一列)
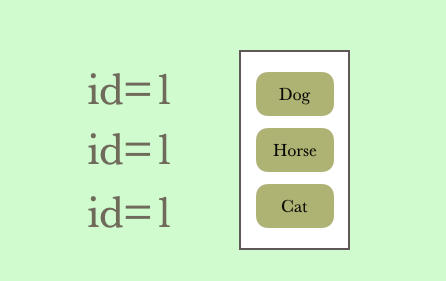
但其实到这里我就产生了一个疑问,为啥要这样设计,直接将普通字段和UDTF 的函数的返回值一起查询不好吗,然后将原始字段和UDTF 的返回值做笛卡尔积就行了啊,为啥还要lateral view 呢,哈哈。
lateral view 中where 的使用
你可能会说where 不就那么用吗,还有啥不一样的,还真有,例如我上面的信息只要刘德华的,那你肯定会写出下面的SQL
select
username,role
from
ods.ods_actor_data
LATERAL VIEW
explode(split(userrole,',')) tmpTable as role
where
username='刘德华'
;要是我只要导演的呢,但是我们知道userrole 这个字段是包没有直接是导演的,但是又包含导演的演员,导演,制片人,幕后,武术指导,其实这个时候你可以用下面的别名字段role
select
username,role
from
ods.ods_actor_data
LATERAL VIEW
explode(split(userrole,',')) tmpTable as role
where
role="导演"
;如图 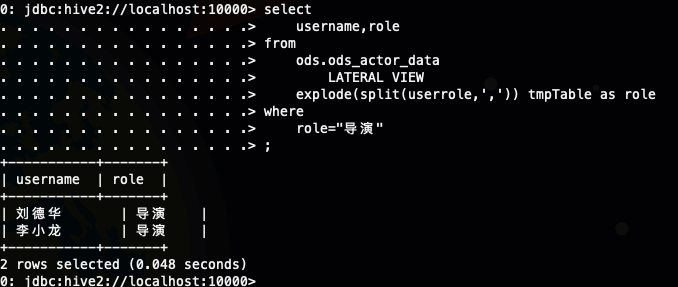
总结
- 一个SQL 里lateral view 你可以多次使用,就会多次做笛卡尔积;
- UDTF 要配合lateral view 一起使用才可以;
- 其实回过头来看的话,我们上面的处理过程就是将一行转化为多行,典型的行转列的实现,是SQL 面试的高频考点;




文章评论