
经常有同学问我,基于Hadoop生态圈的大数据组件有很多,怎么学的过来呢,毕竟精力有限,我们需要有侧重点,我觉得下面这几个组件至关重要,是基础组件,大部分人都需要会的,其它组件可以用的时候再去查查资料学习。
- hadoop
- Hbase
- Hive
- Spark
- Flink
- Kafka
Hadoop
是大数据的基础组件,很多组件都需要依赖它的分布式存储、计算;主要包括Hdfs、MR、Yarn三部分,这个需要找一些好的资料(我的主页有资料领取方法),好好学学各自的用法,熟练之后,需要了解其背后的原理。
基本的,你得知道hadoop安装方法,cdh/hdp等等,启动后几个后台进程各自的作用,namenode高可用,以及高可用基于zk,namenode对元数据fs_image的保存,还有datanode,jobhistoryserver等。
- Hdfs:你需要知道文件的基本操作,命令跟Linux命令差不多,用的时候自然就有机会敲了,上传、下载,回收站,多副本容错(hadoop3的纠删码容错,不使用多副本了,可以节约空间),文件分布式存储的切分,文件存储格式,压缩等待;
- MR:主要是要掌握map -> shuffle -> reduce这一套经典编程模型的原理,MR的基本编写方法,以及map切块,reduce输出,mapjoin优化,内存调优等等;
- Yarn:作为一个资源调度工具,yarn的资源分配(以container为单位,container指的是包含一点cpu和内存),一些常用参数的配置(比如每个应用最多使用资源,每个container资源,虚拟内存率等等),为了任务之间不互相影响,引入资源调度池,将资源隔离开,任务的调度方式(FIFO,fair,capacity)等 YARN调度器(Scheduler)详解;
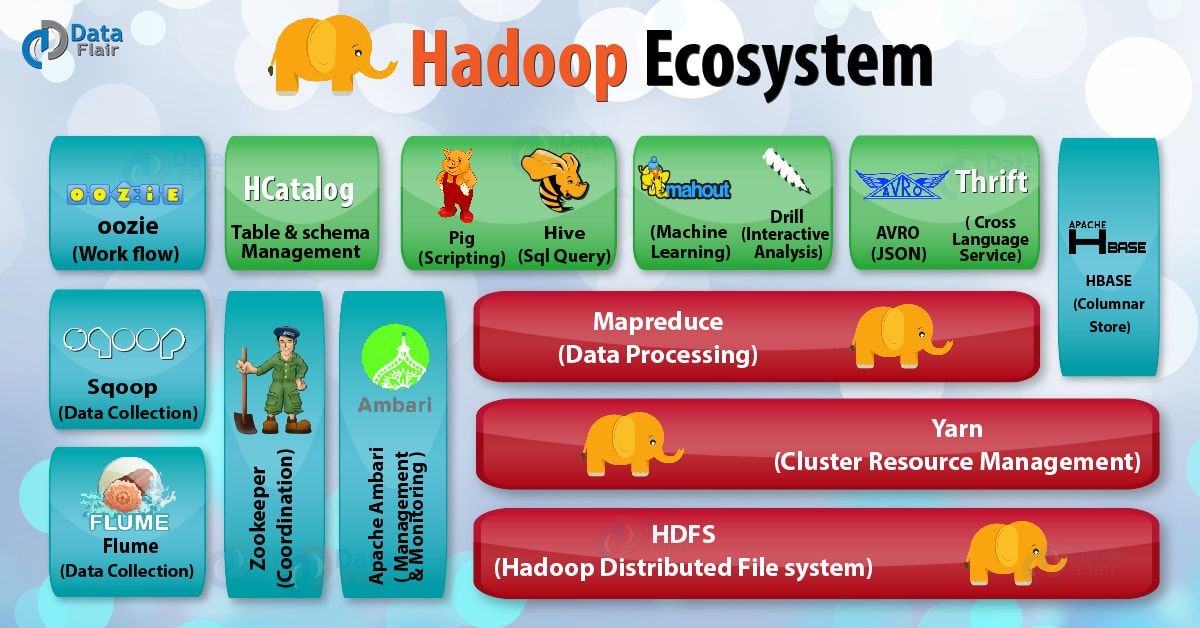
Hbase
这是一个基于Hdfs的列式存储的分布式数据库,在企业中使用普遍,需要重点学习其用法、原理和优化;Hbase集群挂掉的一次惊险经历
需要掌握的基本知识,hbase的基本原理,逻辑上的行与列,列式存储,底层数据hfile基于hdfs,并发高,横向扩展。hbase的HMaster和HRegionServer的作用,zk的作用,客户端读写数据的流程,memstore和bucketcache等缓存,region的分裂,建表预分区,rowkey的设计,数据容错HLog等。
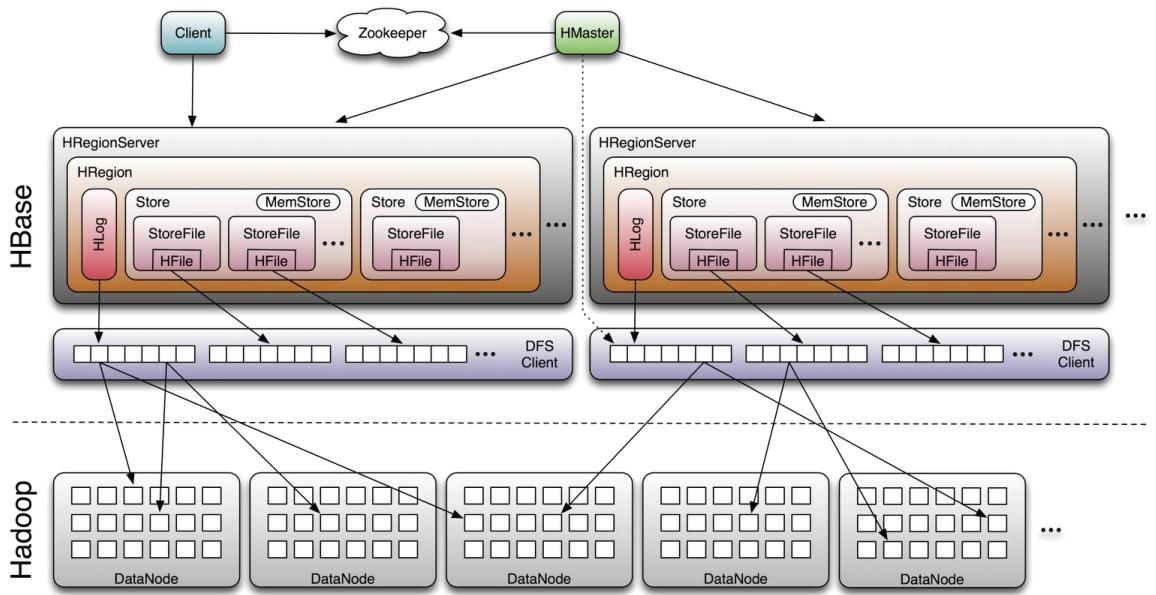
Hive
hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce或者Spark任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
- hive建表,分区表,外部表;
- udf开发和使用,Hiveserver2访问Hive;
- 关联hbase,使用Spark作为执行引擎等;
- join优化;
- 数据倾斜;
- 常用窗口函数;
- 基于Hive搭建数据仓库;
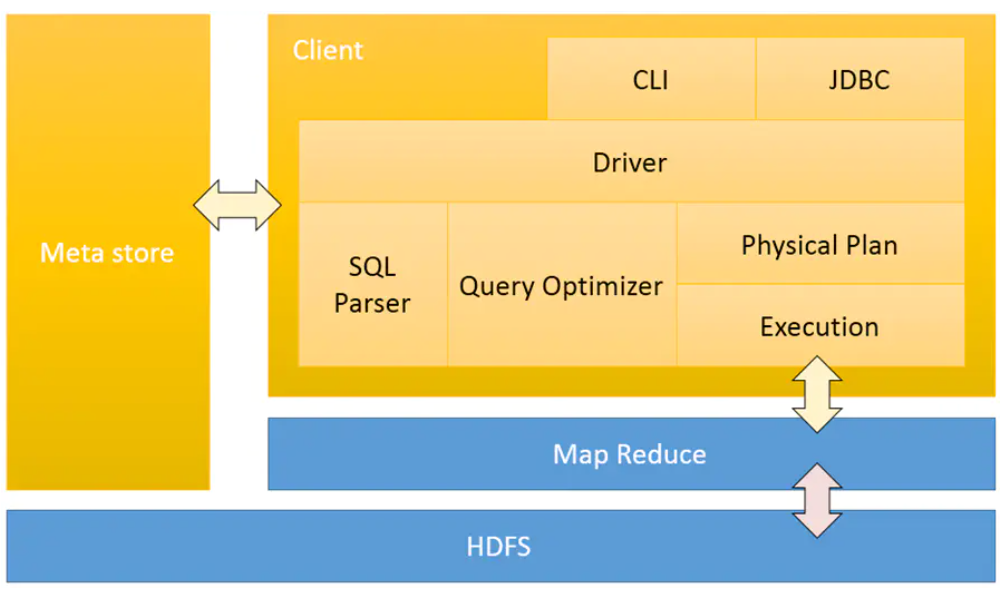
Spark
Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎。Spark使用Scala开发,拥有Hadoop MapReduce所具有的优点,可以进行微批实时处理;但不同于MapReduce的是——Job中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的MapReduce的算法。
- Spark架构,DAG调度器,standalone/yarn/Kubernetes 提供资源运行,内存管理;
- Spark Core,主要包括SparkContext,RDD、action和transform算子;
- SparkStreaming,checkpoint和手动维护offset,消费kafka数据源;
- SQL,DataFrame与RDD的转化;
- Structured Streaming,有点鸡肋,通常用Flink基于event实时处理;
- ML(机器学习),包含了大部分常用的算法,分类、回归、聚类等等;
- Graphx,图计算,有些行业需要用,比如社会关系挖掘、诈骗交易等;
- SparkR,数据科学工作者使用R进行大规模分布式计算,R很耗内存一直是个诟病;
- PySpark,Spark又是很包容的,提供了Python编程的Api;
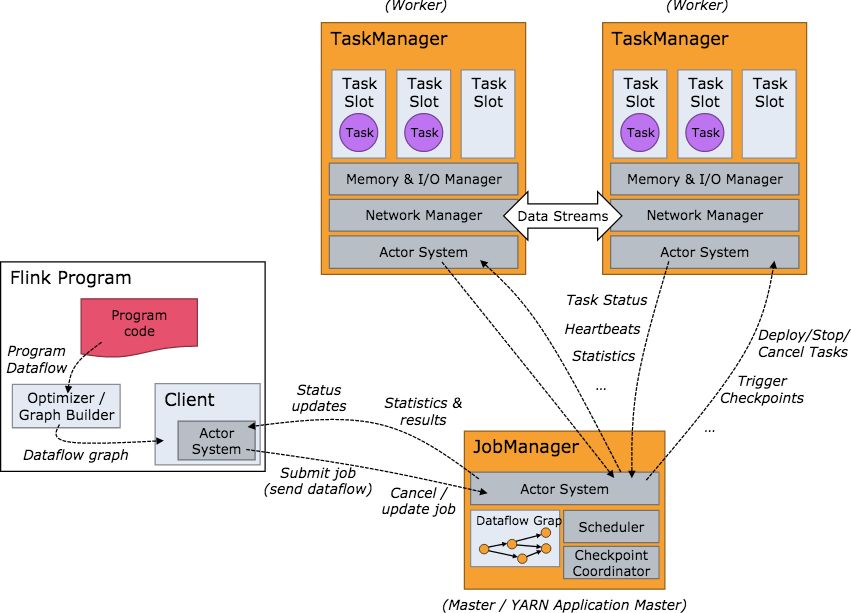
Flink
这是个实时数据处理的组件,企业普遍使用,Flink状态管理与状态一致性(长文)。Apache Flink 是一个框架和分布式处理引擎,用于在无边界和有边界数据流上进行有状态的计算。Flink 能在所有常见集群环境中运行,并能以内存速度和任意规模进行计算。
主要包括,
- Flink的架构,提交应用在Yarn上面;
- DataSet / DataStream / Table Api ;
- Flink流式计算,flink对接kafka数据源;
- 容错,CheckPoint / Savepoint,两阶段提交等;
- Source / Sink操作(hbase、mysql、redis);
- WaterMark机制;
- 窗口函数Window;
- 不同数据流join操作;
- 侧输出(乱序、分流);
- Flink异步IO;
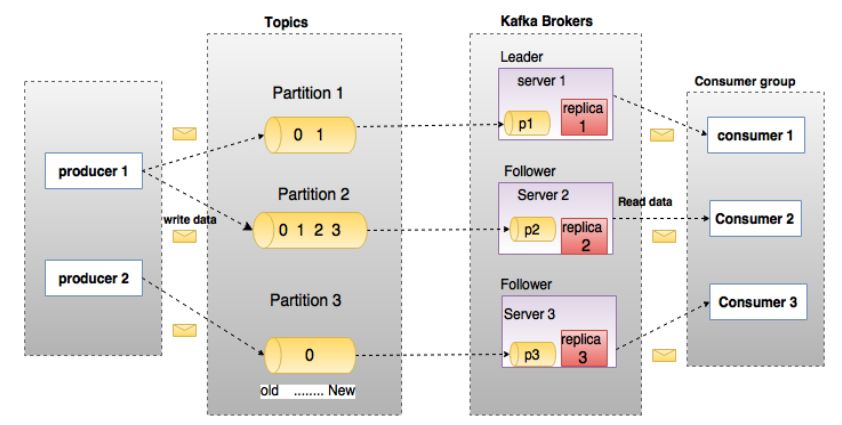
Kafka:Apache Kafka® 是 一个分布式流处理平台。可以让你发布和订阅流式的记录。这一方面与消息队列或者企业消息系统类似。可以储存流式的记录,并且有较好的容错性。可以在流式记录产生时就进行处理。
- 生产者、消费者,消费者组、broker,leader,flower选举等;
- topic,partition,多副本,数据同步,高水位等;
- 抗峰流,数据生命周期;
- 数据写入的acks保证,数据的消费语义,数据的全局和局部有序;
- kafka性能为什么这么快,顺序写、零拷贝、分区并发、传输压缩、时间轮等,面试常问;
- 新版本kafka摒弃了zk;
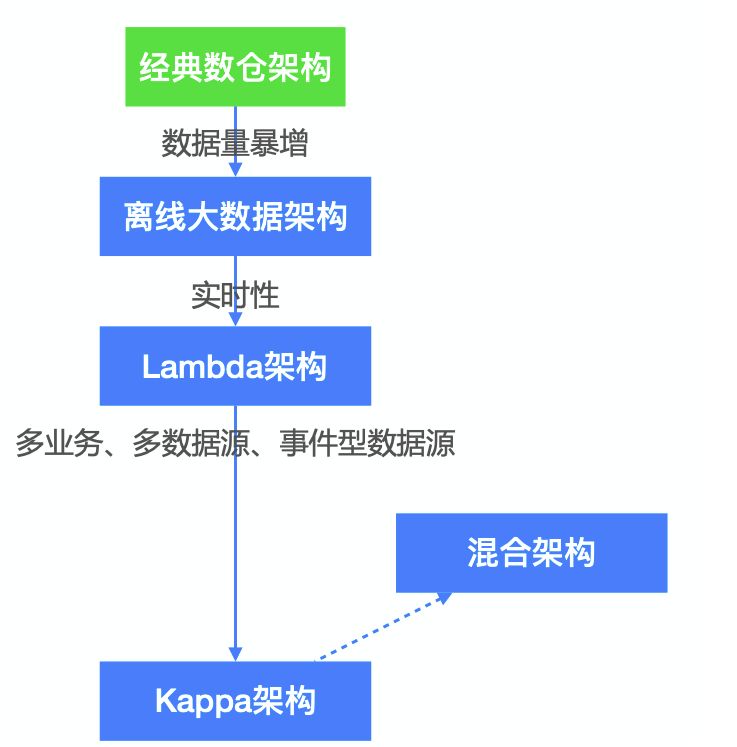
数据仓库
数据仓库是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策,数据仓库在数据平台中的建设有两个环节:一个是数据仓库的构建,另外一个就是数据仓库的应用。数仓架构发展史
- 经典的三范式,维表和事实表;
- 星型模型,雪花模型,星座模型;
- 范式建模和维度建模;
- 数仓分层,ods/dwd/dws/dim, ads层,dm层;
- 数据湖,与数据仓库相比更加灵活和节约成本;
impala
Impala是Cloudera公司主导开发的新型查询系统,它提供SQL语义,能查询存储在Hadoop的HDFS和HBase中的PB级大数据。已有的Hive系统虽然也提供了SQL语义,但由于Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性。相比之下,Impala的最大特点也是最大卖点就是它的快速。
clickhouse
ClickHouse 是 Yandex(俄罗斯最大的搜索引擎)开源的一个用于实时数据分析的基于列存储的数据库,其处理数据的速度比传统方法快 100-1000 倍。
kylin
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 开发并贡献至开源社区。它能在亚秒内查询巨大的表。
Apache Kylin™ 令使用者仅需三步,即可实现超大数据集上的亚秒级查询。
- 定义数据集上的一个星形或雪花形模型
- 在定义的数据表上构建cube
- 使用标准 SQL 通过 ODBC、JDBC 或 RESTFUL API 进行查询,仅需亚秒级响应时间即可获得查询结果
**docker / Kubernetes **
Kubernetes 是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。 Kubernetes 拥有一个庞大且快速增长的生态系统。Kubernetes 的服务、支持和工具广泛可用。
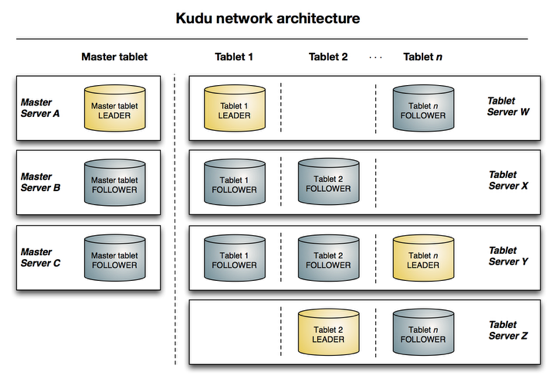
kudu
Kudu是Cloudera开源的新型列式存储系统,是Apache Hadoop生态圈的成员之一(incubating),专门为了对快速变化的数据进行快速的分析,填补了以往Hadoop存储层的空缺。
cdh/hdp
Apache Hadoop的开源协议决定了任何人可以对其进行修改,并作为开源或者商业版发布/销售。故而目前Hadoop发行版非常的多,有华为发行版(收费)、Intel发行版(收费)、Cloudera发行版CDH(免费)、Hortonworks版本HDP(免费),这些发行版都是基于Apache Hadoop衍生出来的。
当然了,还有很多其它的组件,比如sqoop,oozie等等,都有自己的应用场景。




文章评论