
摘要:在本教程中,您将学习如何使用MySQL DISTINCT子句来去除结果集中的重复行。
介绍MySQL DISTINCT子句
当从表中查询数据时,您可能会得到重复的行。为了删除这些重复行,可以在SELECT语句中使用DISTINCT 子句。
使用DISTINCT 子句的语法如下:
SELECT DISTINCT
columns
FROM
table_name
WHERE
where_conditions;
MySQL DISTINCT示例
让我们来看一个使用DISTINCT 子句的简单示例,从employees表中查询员工的姓氏有哪些。
首先,我们使用SELECT语句从表employees中查询员工的姓氏,如下所示:
SELECT
lastname
FROM
employees
ORDER BY lastname;
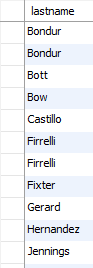
有些员工拥有相同的姓氏 Bondur,Firrelli等等。
要删除重复的姓氏,请将DISTINCT 语句添加到SELECT语句中 ,如下所示:
SELECT DISTINCT
lastname
FROM
employees
ORDER BY lastname;
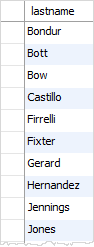
当我们使用DISTINCT 子句时,重复的姓氏在结果集中被去除。
MySQL DISTINCT与NULL
如果一个列(字段)具有NULL值,并且您在该列(字段)中使用了DISTINCT 子句,那么MySQL将保留一个NULL值并消除另一个值,因为DISTINCT 子句将所有NULL值视为相同的值。
例如,在customers表中,我们有许多数据行的 state列为NULL。当我们使用DISTINCT 子句查询客户的state时,我们将看到state的唯一NULL值,mysql语句如下:
SELECT DISTINCT
state
FROM
customers;
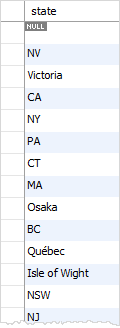
在MySQL DISTINCT中使用多列
您可以对多个列使用DISTINCT子句。在这种情况下,MySQL使用所有列的组合来确定结果集中行的唯一性。
例如,要从customers表中获取city和state的唯一组合,请使用以下查询:
SELECT DISTINCT
state, city
FROM
customers
WHERE
state IS NOT NULL
ORDER BY state , city;
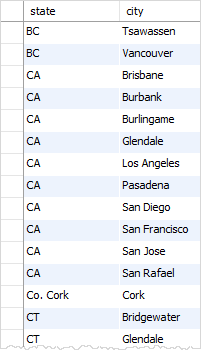
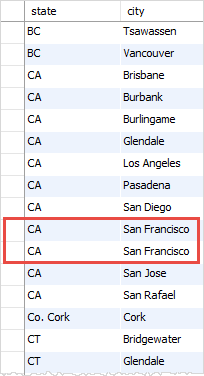
如何没有使用DISTINCT 子句,您将获得city和state的重复组合如下:
SELECT
state, city
FROM
customers
WHERE
state IS NOT NULL
ORDER BY state , city;
DISTINCT子句与GROUP BY子句
如果在SELECT语句中使用了GROUP BY子句而没有不使用聚合函数,则GROUP BY子句的作用类似于DISTINCT 子句。
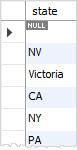
以下语句使用GROUP BY子句来查询customers表中客户的唯一state。
SELECT
state
FROM
customers
GROUP BY state;

您也可以通过使用以下DISTINCT子句来实现类似的结果:
SELECT DISTINCT
state
FROM
customers;
一般来说,DISTINCT 子句是特殊情况下的GROUP BY子句。DISTINCT 子句和GROUP BY子句之间的区别是GROUP BY子句对结果集进行排序,而DISTINCT 子句不排序。
如果将ORDER BY添加到 DISTINCT子句的语句中,则结果集将进行排序,并且与使用GROUP BY子句的语句返回结果相同。
SELECT DISTINCT
state
FROM
customers
ORDER BY state;
MySQL DISTINCT与聚合函数
您可以使用带有聚合函数的DISTINCT(如SUM,AVG和COUNT)子句,在删除重复数据之后,MySQL将聚合函数应用于结果集中。
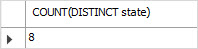
例如,要计算美国客户的唯一state,请使用以下查询:
SELECT
COUNT(DISTINCT state)
FROM
customers
WHERE
country = 'USA';
带有LIMIT的MySQL DISTINCT
在使用带有LIMIT的DISTINCT子句的情况下,MySQL只返回LIMIT范围内的唯一不重复的结果集。
以下mysql语句查询customers表中的前5个非空的唯一state。
SELECT DISTINCT
state
FROM
customers
WHERE
state IS NOT NULL
LIMIT 5;

在本教程中,我们向您介绍了如何使用MySQL DISTINCT 子句的各种方法,如去除重复数据和计算非NULL值。




文章评论