
MySQL HAVING子句
MySQL的HAVING子句在SELECT语句中是用来为某一组行或聚合指定过滤条件。
MySQL的HAVING子句通常与GROUP BY子句一起使用。当它在GROUP BY子句中使用时,我们可以应用它在GROUP BY子句之后来指定过滤的条件。如果省略了GROUP BY子句,HAVING子句行为就像WHERE子句一样。
请注意,HAVING子句应用筛选条件每一个分组的行,而WHERE子句的过滤条件是过滤每个单独的行。
MySQL HAVING子句实例
我们来看一下使用MySQL HAVING子句的例子。为了演示,我们将使用示例数据库中的orderdetails表。

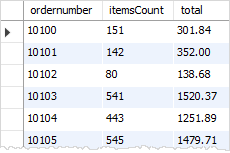
我们可以使用GROUP BY子句来获得订单编号,每个订单销售的产品数量,以及每个订单的总额:
SELECT
ordernumber,
SUM(quantityOrdered) AS itemsCount,
SUM(priceeach) AS total
FROM
orderdetails
GROUP BY ordernumber;
结果如下:
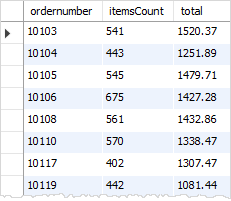
现在,要查找那些销售总额超过 1000 的订单信息。使用MySQL HAVING子句和聚合函数如下:
SELECT
ordernumber,
SUM(quantityOrdered) AS itemsCount,
SUM(priceeach) AS total
FROM
orderdetails
GROUP BY ordernumber
HAVING total > 1000;
结果如下:
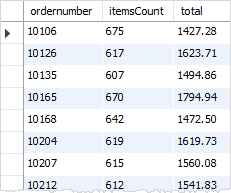
我们还可以构造并使用逻辑运算符,如在HAVING子句中OR和AND运算符实现更复杂一点的过滤条件。假设要查找 order 表中总销售额大于1000,并且一个订单中包含 600 种以上的产品,参考使用下面的查询:
SELECT
ordernumber,
SUM(quantityOrdered) AS itemsCount,
SUM(priceeach) AS total
FROM
orderdetails
GROUP BY ordernumber
HAVING total > 1000 AND itemsCount > 600;
结果如下:
假设要查找已发货(status=Shipped)并且总销售额超过 1500 的所有订单,我们可以通过使用INNER JOIN子句将 order 表连接 order_detail 表,并在 status 和 total 列上指定条件,如下查询所示:
SELECT
a.ordernumber, SUM(priceeach) total, status
FROM
orderdetails a
INNER JOIN
orders b ON b.ordernumber = a.ordernumber
GROUP BY ordernumber
HAVING b.status = 'Shipped' AND total > 1500;
结果如下:

当我们要通过GROUP BY子句来实现高级的报表输出时,使用HAVING子句就非常有用了。例如,我们可以使用HAVING子句来实现一些类似的查询,如:这个月,本季度和今年累计销售额超过10000 的订单信息。
MYSQL having与where区别
讲解一:
我们在写sql语句的时候,经常会使用where语句,很少会用到having,其实在mysql中having子句也是设定条件的语句与where有相似之处但也有区别。having子句在查询过程中慢于聚合语句(sum,min,max,avg,count).而where子句在查询过程中则快于聚合语(sum,min,max,avg,count)。
简单说来:
where子句:
select sum(num) as rmb from order where id>10
//先查询出id大于10的记录才能进行聚合语句
having子句:
select reportsto as manager, count(*) as reports from employees
group by reportsto having count(*) > 4
以test库为例.having条件表达示为聚合语句。肯定的说having子句查询过程慢于聚合语句。
再换句说话说把上面的having换成where则会出错。统计分组数据时用到聚合语句。
对分组数据再次判断时要用having。如果不用这些关系就不存在使用having。直接使用where就行了。
having就是来弥补where在分组数据判断时的不足。因为where要快于聚合语句。
讲解二:
让我们先运行2个sql语句:
1、SELECT * FROM `welcome` HAVING id >1 LIMIT 0 , 30
2、SELECT * FROM `welcome` WHERE id >1 LIMIT 0 , 30
查看一下结果吧,怎么样?是不是查询到相同的结果。
让我们再看2个sql语句:
1、SELECT user, MAX(salary) FROM users GROUP BY user HAVING MAX(salary)>10;
2、SELECT user, MAX(salary) FROM users GROUP BY user WHERE MAX(salary)>10;
怎么样?看出差别了吗,第一个sql语句可以正常运行【旧版mysql可能会出错】,而第二个则会报错。
看了2个实例之后,我们再来看mysql手册中对having语句的说明:
1、SQL标准要求HAVING必须引用GROUP BY子句中的列或用于总计函数中的列。不过,MySQL支持对此工作性质的扩展,并允许HAVING涉及SELECT清单中的列和外部子查询中的列。
2、HAVING子句必须位于GROUP BY之后ORDER BY之前。
3、如果HAVING子句引用了一个意义不明确的列,则会出现警告。在下面的语句中,col2意义不明确,因为它既作为别名使用,又作为列名使用:mysql> SELECT COUNT(col1) AS col2 FROM t GROUP BY col2 HAVING col2 = 2;
标准SQL工作性质具有优先权,因此如果一个HAVING列名既被用于GROUP BY,又被用作输出列清单中的起了别名的列,则优先权被给予GROUP BY列中的列。
4、HAVING子句可以引用总计函数,而WHERE子句不能引用。【这应该是开发者在特定的情况下采用HAVING子句的最大原因】
5、不要将HAVING用于应被用于WHERE子句的条目,从我们开头的2条语句来看,这样用并没有出错,但是mysql不推荐。而且也没有明确说明原因,但是既然它要求,我们遵循就可以了。




文章评论