
关注公众号:大数据技术派,回复"资料",领取
1024G资料。
2015 年,Flink 的作者就写了 Apache Flink: Stream and Batch Processing in a Single Engine 这篇论文。本文以这篇论文为引导,详细讲讲 Flink 内部是如何设计并实现批流一体的架构。
前言
通常我们在 Flink 中说批流一体指的是这四个方向,其中 Runtime 便是 Flink 运行时的实现。
数据交换模型
Flink 对于流作业和批作业有一个统一的执行模型。
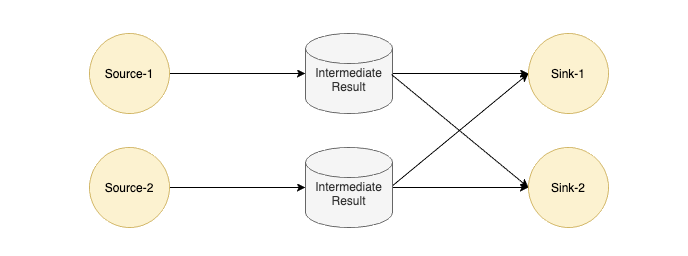
Flink 中每个 Task 的输出会以 IntermediateResult 做封装,内部并没有对流和批两种作业做一个明确的划分,只是通过不同类型的 IntermediateResult 来表达 PIPELINED 和 BLOCKING 这两大类数据交换模型。
在了解数据交换模型之前,我们来看下为什么 Flink 对作业类型不作区分,这样的好处是什么?
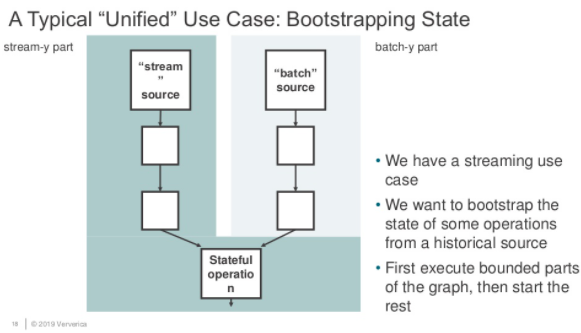
如上图所示,假如我们有一个工作需要将批式作业执行结果作为流式作业的启动输入,那怎么办?这个作业是算批作业还是流作业?
很显然,以我们的常识是无法定义的,而现有的工业界的办法也是如此,将这个作业拆分为两个作业,先跑批式作业,再跑流式作业,这样当然可以,但是人工运维的成本也是足够大的:
- 需要一个外界存储来管理批作业的输出数据。
- 需要一个支持批流作业依赖的调度系统。
如果期望实现这样一个作业,那么首先执行这个作业的计算引擎的作业属性就不能对批作业和流作业进行强绑定。那么 Flink 能否实现这样的需求呢?我们先来看看数据交换的具体细节,最后再来一起看看这个作业的可行性。
我们以 PIPELINED 数据交换模型为例,看看是如何设计的:
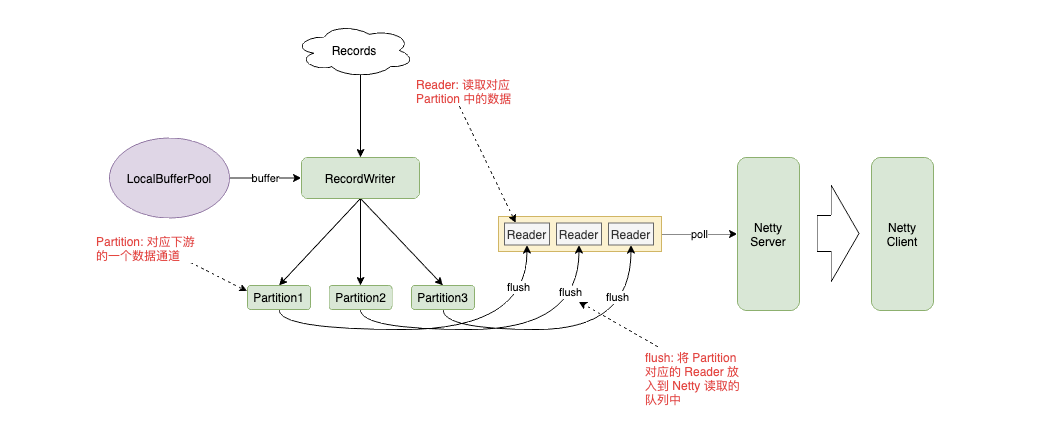
PIPELINED 模式下,RecordWriter 将数据放入到 Buffer 中,根据 Key 的路由规则发送给对应的 Partition,Partition 将自己的数据封装到 Reader 中放入队列,让 Netty Server 从队列中读取数据,发送给下游。
我们将数据交换模式改为 BLOCKING,会发现这个设计也是同样可行的。Partition 将数据写入到文件,而 Reader 中维护着文件的句柄,上游任务结束后调度下游任务,而下游任务通过 Netty Client 的 Partition Request 唤醒对应的 Partition 和 Reader,将数据拉到下游。
调度模型
有 LAZY 和 EAGER 两种调度模型,默认情况下流作业使用 EAGER,批作业使用 LAZY。
EAGER
这个很好理解,因为流式作业是 All or Nothing 的设计,要么所有 Task 都 Run 起来,要么就不跑。
LAZY
LAZY 模式就是先调度上游,等待上游产生数据或结束后再调度下游。有些类似 Spark 中的 Stage 执行模式。
Region Scheduling
可以看到,不管是 EAGER 还是 LAZY 都没有办法执行我们刚才提出的批流混合的任务,于是社区提出了 Region Scheduling 来统一批流作业的调度,我们先看一下如何定义 Region:
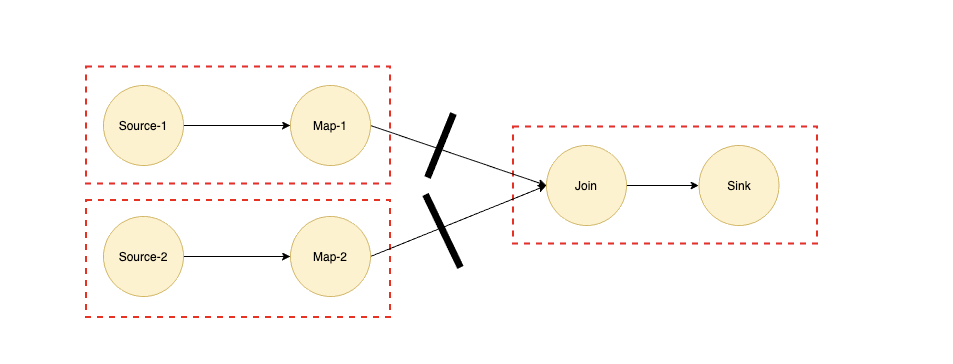
以 Join 算子为例,我们都知道如果 Join 算子的两个输入都是海量数据的话,那么我们是需要等两个输入的数据都完全准备好才能进行 Join 操作的,所以 Join 两条输入的边对应的数据交换模式对应的应该是 BLOCKING 模式,我们可以根据 BLOCKING 的边将作业划分为多个子 Region,如上图虚线所示。
如果实现了 Region Scheduling 之后,我们在上面提到的批流混合的作业就可以将深色部分流式作业划为一个 Region,浅色部分批式作业再划分为多个 Region,而浅色部分是深色部分 Region 的输入,所以根据 Region Scheduling 的原则会优先调度最前面的 Region。
总结
上面提到了数据交换模型和调度模型,简单来讲其实就两句话:
1 实现了用 PIPELINED 模型去跑批式作业
用 PIPELINED 模型跑流式作业和用 BLOCKING 模型跑批式作业都是没有什么新奇的。这里提到用 PIPELINED 模式跑批作业,主要是针对实时分析的场景,以 Spark 为例,在大部分出现 Shuffle 或是聚合的场景下都会出现落盘的行为,并且调度顺序是一个一个 Stage 进行调度,极大地降低了数据处理的实时性,而使用 PIPELINED 模式会对性能有一定提升。
可能有人会问类似 Join 的算子如何使用 PIPELINED 数据交换模型实现不落盘的操作?事实上 Flink 也会落盘,只不过不是在 Join 的两个输入端落盘,而是将两个输入端的数据传输到 Join 算子上,内存撑不住时再进行落盘,海量数据下和 Spark 的行为并没有本质区别,但是在数据量中等,内存可容纳的情况下会带来很大的收益。
2 集成了一部分调度系统的功能
根据 Region 来调度作业时,Region 内部跑的具体是流作业还是批作业,Flink 自身是不关心的,更关心的 Region 之间的依赖关系,一定程度上,利用这种调度模型我们可以将过去需要拆分为多个作业的执行模式放到一个作业中来执行,比如上面提到的批流混合的作业。
猜你喜欢
Spark SQL知识点与实战
Hive计算最大连续登陆天数
Hadoop 数据迁移用法详解
Hbase修复工具Hbck
数仓建模分层理论
大数据组件重点学习这几个




文章评论