
并不是索引越多越好,索引是一种以空间换取时间的方式,所以建立索引是要消耗一定的空间,况且在索引的维护上也会消耗资源。
这里有张用户浏览商品表,建表语句:
CREATE TABLE `product_view` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`user_id` int(11) NOT NULL,
`product_id` int(11) NOT NULL,
`server_id` int(11) NOT NULL,
`duration` int(11) NOT NULL,
`times` varchar(11) NOT NULL,
`time` datetime NOT NULL,
PRIMARY KEY (`id`),
KEY `time` (`time`),
KEY `user_product` (`user_id`,`product_id`) USING BTREE,
KEY `times` (`times`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4;可以看出目前这张表是有3个索引的:

我往这张表里面导入了10万多条记录。
mysql不走索引的情况
1、like查询以“%”开头(如果开头、结果都有“%”,也不会使用索引,走的是全表扫描);
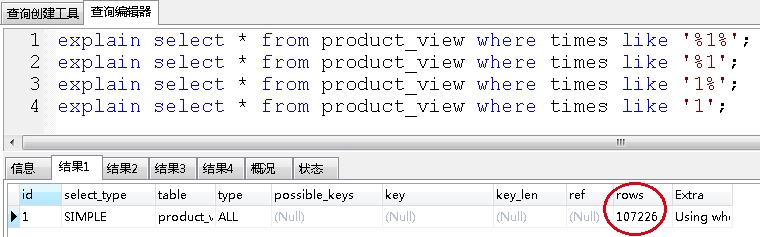
我这里用了列出了4种情况,发现都是全表扫描,不走索引的。可能因为times取值不够离散,索引没有走索引。
2、or语句前后没有同时使用索引;
首先看看or语句前后同时使用索引:
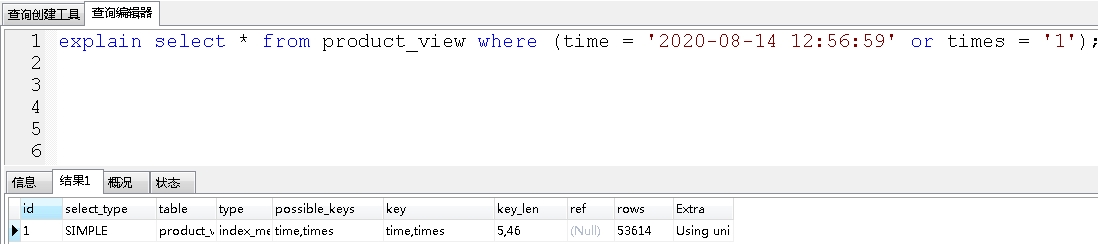
查询走索引了。
再看看or语句前后没有同时使用索引,product_id是索引字段,server_id不是索引字段:
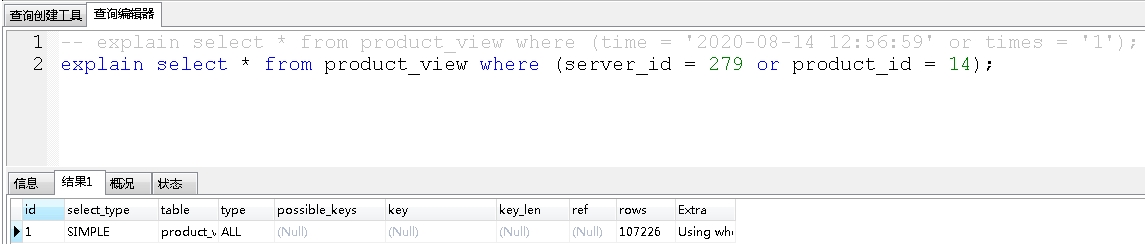
是没有走索引的。
3、组合索引中不是使用第一列索引;(不符合最左匹配原则)
这张表索引为时间time和一个组合索引:
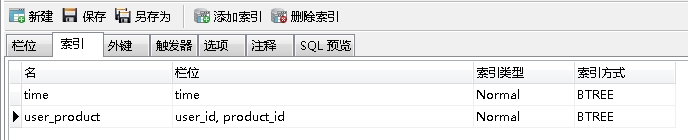
这里组合索引user_product,我们先使用user_id这个第一列索引,作为查询条件,查看执行计划:
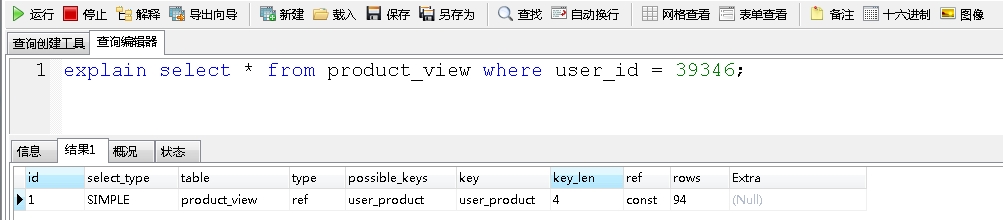
使用了索引。
接下来使用组合索引user_product的非第一列索引product_id,再看看执行计划:

没有使用索引。
4、where条件中类型为字符串的字段没有使用引号引起来;【查询where条件数据类型不匹配也无法使用索引,字符串与数字比较不使用索引,因为正则表达式不使用索引,如varchar不加单引号的话可能会自动转换为int型,使索引无效,产生全表扫描】
首先看看where后条件字符串正常使用引号:
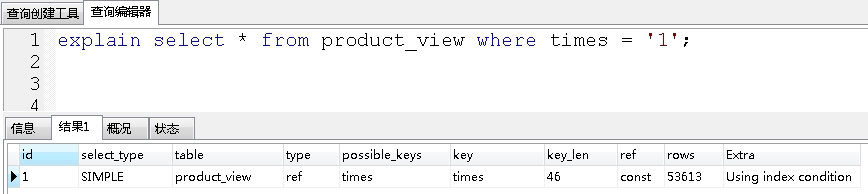
使用了索引。
where后条件字符串不使用引号,而使用数字:
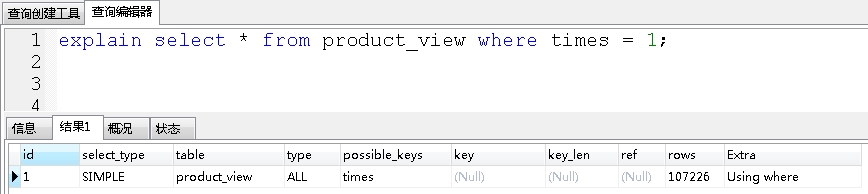
可以看到,查询没有走索引。
5、当全表扫描速度比索引速度快时,mysql会使用全表扫描,此时索引失效;(*数据量少*)
我把表数据删了,里面留了7条数据:
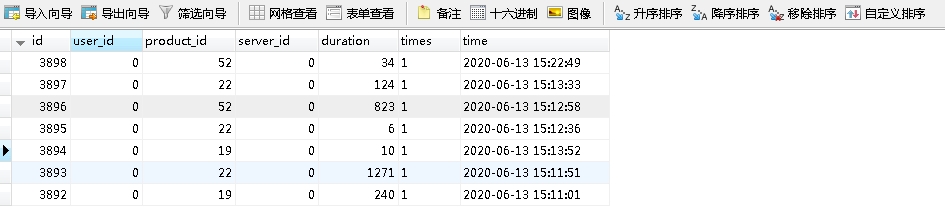
条件查询索引字段列times:
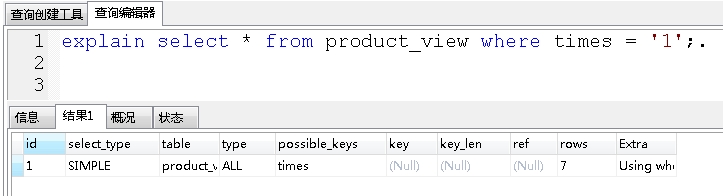
显然是没有走索引的。
6、在索引字段上使用“not”,“<>”,“!=”等等;
经过验证发现,使用这些符号后,依然会走索引。
7、对索引字段进行计算操作、使用函数;
MySql 如果表中某个时间字段(datetime/…)设置了索引,以函数 DATE_FORMAT() 为查询条件时,为datetime设置的索引不生效,会引起全表扫描导致查询很慢。
没有用函数时候是走了索引的,查出具体到时分秒的数据:
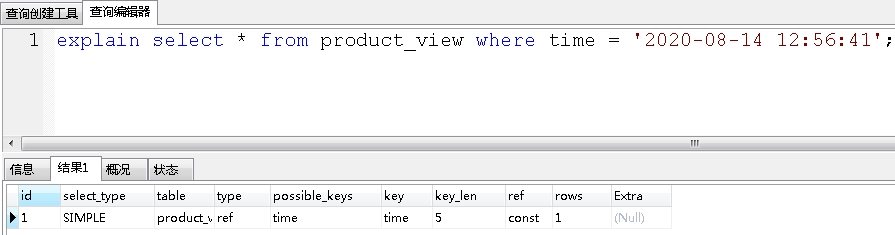
使用函数data_format函数,查出2020-08-14这一天的所有数据:
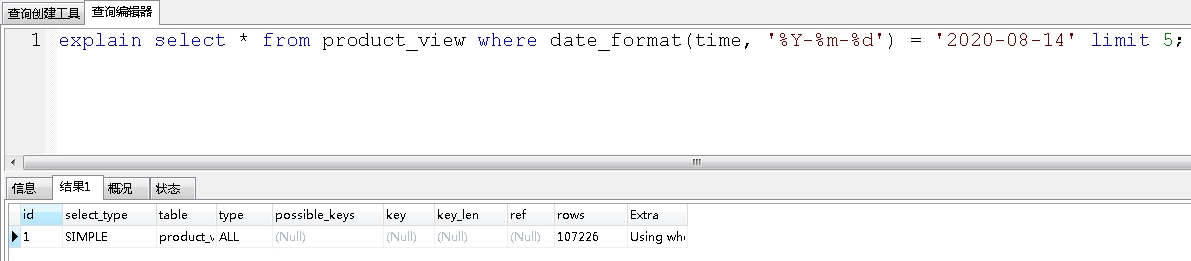
没有走索引,那么怎么解决呢?
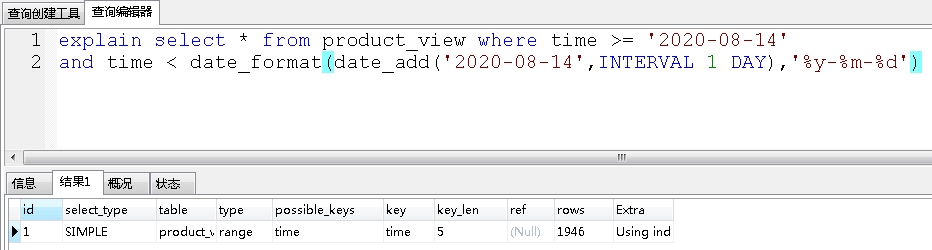
如果一定要用函数,比如date_format,可以通过这种方式,就会走索引。
8、索引散列值(重复多)不适合建索引,例:性别、状态等字段不适合。
不应该建立索引的字段规则
-
不应该在字段比较长的字段上建立索引,因为会消耗大量的空间
-
对于频繁更新、插入的字段应该少建立索引,因为在修改和插入之后,数据库会去维护索引,会消耗资源
-
尽量少在无用字段上建立索引【where条件中用不到的字段】
-
表记录太少不应该创建索引
-
数据重复且分布平均的表字段不应该创建索引【选择性太低,例如性别、状态、真假值等字段】
-
参与列计算的列不适合建索引【保持列"干净",比如from_unixtime(create_time) = '2014-05-29'就不能使用到索引,原因是b+树中存的都是数据表中的字段值,但进行检索时需要把所有元素都应用函数才能比较,显然成本太大,所以语句应该写成create_time = unix_timestamp('2014-05-29')】




文章评论