Flink系列文章
- 第01讲:Flink 的应用场景和架构模型
- 第02讲:Flink 入门程序 WordCount 和 SQL 实现
- 第03讲:Flink 的编程模型与其他框架比较
- 第04讲:Flink 常用的 DataSet 和 DataStream API
- 第05讲:Flink SQL & Table 编程和案例
- 第06讲:Flink 集群安装部署和 HA 配置
- 第07讲:Flink 常见核心概念分析
- 第08讲:Flink 窗口、时间和水印
- 第09讲:Flink 状态与容错
- 第10讲:Flink Side OutPut 分流
- 第11讲:Flink CEP 复杂事件处理
- 第12讲:Flink 常用的 Source 和 Connector
- 第13讲:如何实现生产环境中的 Flink 高可用配置
- 第14讲:Flink Exactly-once 实现原理解析
- 第15讲:如何排查生产环境中的反压问题
在 Flink 这个框架中,有很多独有的概念,比如分布式缓存、重启策略、并行度等,这些概念是我们在进行任务开发和调优时必须了解的,这一课时我将会从原理和应用场景分别介绍这些概念。
分布式缓存
熟悉 Hadoop 的你应该知道,分布式缓存最初的思想诞生于 Hadoop 框架,Hadoop 会将一些数据或者文件缓存在 HDFS 上,在分布式环境中让所有的计算节点调用同一个配置文件。在 Flink 中,Flink 框架开发者们同样将这个特性进行了实现。
Flink 提供的分布式缓存类型 Hadoop,目的是为了在分布式环境中让每一个 TaskManager 节点保存一份相同的数据或者文件,当前计算节点的 task 就像读取本地文件一样拉取这些配置。
分布式缓存在我们实际生产环境中最广泛的一个应用,就是在进行表与表 Join 操作时,如果一个表很大,另一个表很小,那么我们就可以把较小的表进行缓存,在每个 TaskManager 都保存一份,然后进行 Join 操作。
那么我们应该怎样使用 Flink 的分布式缓存呢?举例如下:
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.registerCachedFile("/Users/wangzhiwu/WorkSpace/quickstart/distributedcache.txt", "distributedCache");
//1:注册一个文件,可以使用hdfs上的文件 也可以是本地文件进行测试
DataSource<String> data = env.fromElements("Linea", "Lineb", "Linec", "Lined");
DataSet<String> result = data.map(new RichMapFunction<String, String>() {
private ArrayList<String> dataList = new ArrayList<String>();
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
//2:使用该缓存文件
File myFile = getRuntimeContext().getDistributedCache().getFile("distributedCache");
List<String> lines = FileUtils.readLines(myFile);
for (String line : lines) {
this.dataList.add(line);
System.err.println("分布式缓存为:" + line);
}
}
@Override
public String map(String value) throws Exception {
//在这里就可以使用dataList
System.err.println("使用datalist:" + dataList + "-------" +value);
//业务逻辑
return dataList +":" + value;
}
});
result.printToErr();
}从上面的例子中可以看出,使用分布式缓存有两个步骤。
- 第一步:首先需要在 env 环境中注册一个文件,该文件可以来源于本地,也可以来源于 HDFS ,并且为该文件取一个名字。
- 第二步:在使用分布式缓存时,可根据注册的名字直接获取。
可以看到,在上述案例中,我们把一个本地的 distributedcache.txt 文件注册为 distributedCache,在下面的 map 算子中直接通过这个名字将缓存文件进行读取并且进行了处理。
我们直接运行该程序,在控制台可以看到如下输出:


在使用分布式缓存时也需要注意一些问题,需要我们缓存的文件在任务运行期间最好是只读状态,否则会造成数据的一致性问题。另外,缓存的文件和数据不宜过大,否则会影响 Task 的执行速度,在极端情况下会造成 OOM。
故障恢复和重启策略
自动故障恢复是 Flink 提供的一个强大的功能,在实际运行环境中,我们会遇到各种各样的问题从而导致应用挂掉,比如我们经常遇到的非法数据、网络抖动等。
Flink 提供了强大的可配置故障恢复和重启策略来进行自动恢复。
故障恢复
我们在上一课时中介绍过 Flink 的配置文件,其中有一个参数 jobmanager.execution.failover-strategy: region。
Flink 支持了不同级别的故障恢复策略,jobmanager.execution.failover-strategy 的可配置项有两种:full 和 region。
当我们配置的故障恢复策略为 full 时,集群中的 Task 发生故障,那么该任务的所有 Task 都会发生重启。而在实际生产环境中,我们的大作业可能有几百个 Task,出现一次异常如果进行整个任务重启,那么经常会导致长时间任务不能正常工作,导致数据延迟。
但是事实上,我们可能只是集群中某一个或几个 Task 发生了故障,只需要重启有问题的一部分即可,这就是 Flink 基于 Region 的局部重启策略。在这个策略下,Flink 会把我们的任务分成不同的 Region,当某一个 Task 发生故障时,Flink 会计算需要故障恢复的最小 Region。
Flink 在判断需要重启的 Region 时,采用了以下的判断逻辑:
- 发生错误的 Task 所在的 Region 需要重启;
- 如果当前 Region 的依赖数据出现损坏或者部分丢失,那么生产数据的 Region 也需要重启;
- 为了保证数据一致性,当前 Region 的下游 Region 也需要重启。
重启策略
Flink 提供了多种类型和级别的重启策略,常用的重启策略包括:
- 固定延迟重启策略模式
- 失败率重启策略模式
- 无重启策略模式
Flink 在判断使用的哪种重启策略时做了默认约定,如果用户配置了 checkpoint,但没有设置重启策略,那么会按照固定延迟重启策略模式进行重启;如果用户没有配置 checkpoint,那么默认不会重启。
下面我们分别对这三种模式进行详细讲解。
无重启策略模式
在这种情况下,如果我们的作业发生错误,任务会直接退出。
我们可以在 flink-conf.yaml 中配置:
复制代码
restart-strategy: none也可以在程序中使用代码指定:
复制代码
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setRestartStrategy(RestartStrategies.noRestart());固定延迟重启策略模式
固定延迟重启策略会通过在 flink-conf.yaml 中设置如下配置参数,来启用此策略:
复制代码
restart-strategy: fixed-delay固定延迟重启策略模式需要指定两个参数,首先 Flink 会根据用户配置的重试次数进行重试,每次重试之间根据配置的时间间隔进行重试,如下表所示:

举个例子,假如我们需要任务重试 3 次,每次重试间隔 5 秒,那么需要进行一下配置:
复制代码
restart-strategy.fixed-delay.attempts: 3
restart-strategy.fixed-delay.delay: 5 s当前我们也可以在代码中进行设置:
复制代码
env.setRestartStrategy(RestartStrategies.fixedDelayRestart(
3, // 重启次数
Time.of(5, TimeUnit.SECONDS) // 时间间隔
));失败率重启策略模式
首先我们在 flink-conf.yaml 中指定如下配置:
复制代码
restart-strategy: failure-rate这种重启模式需要指定三个参数,如下表所示。失败率重启策略在 Job 失败后会重启,但是超过失败率后,Job 会最终被认定失败。在两个连续的重启尝试之间,重启策略会等待一个固定的时间。
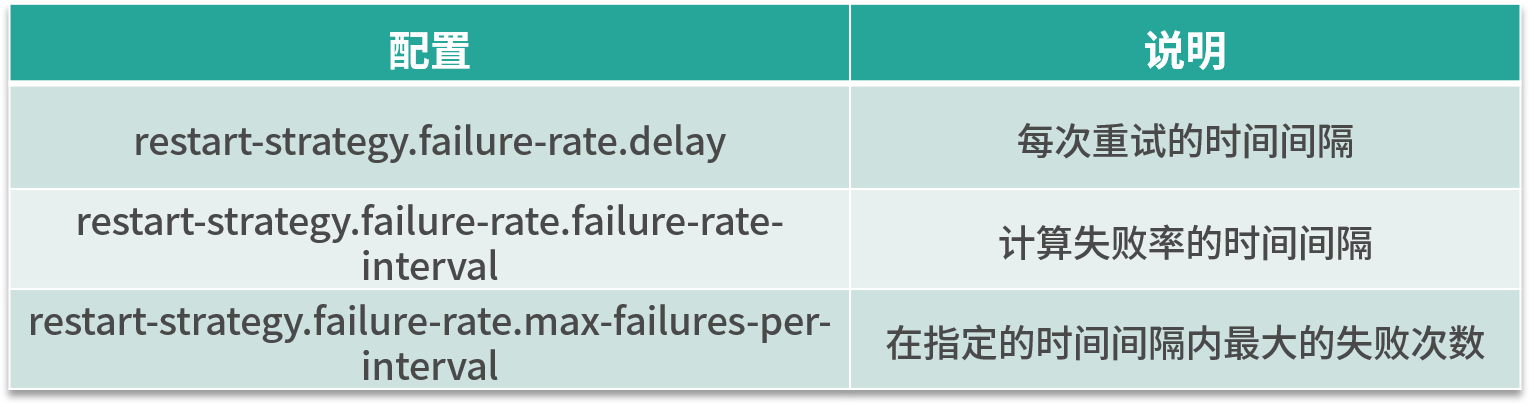
这种策略的配置理解较为困难,我们举个例子,假如 5 分钟内若失败了 3 次,则认为该任务失败,每次失败的重试间隔为 5 秒。
那么我们的配置应该是:
复制代码
restart-strategy.failure-rate.max-failures-per-interval: 3
restart-strategy.failure-rate.failure-rate-interval: 5 min
restart-strategy.failure-rate.delay: 5 s当然,也可以在代码中直接指定:
复制代码
env.setRestartStrategy(RestartStrategies.failureRateRestart(
3, // 每个时间间隔的最大故障次数
Time.of(5, TimeUnit.MINUTES), // 测量故障率的时间间隔
Time.of(5, TimeUnit.SECONDS) // 每次任务失败时间间隔
));最后,需要注意的是,在实际生产环境中由于每个任务的负载和资源消耗不一样,我们推荐在代码中指定每个任务的重试机制和重启策略。
并行度
并行度是 Flink 执行任务的核心概念之一,它被定义为在分布式运行环境中我们的一个算子任务被切分成了多少个子任务并行执行。我们提高任务的并行度(Parallelism)在很大程度上可以大大提高任务运行速度。
一般情况下,我们可以通过四种级别来设置任务的并行度。
- 算子级别
在代码中可以调用 setParallelism 方法来设置每一个算子的并行度。例如:
复制代码
DataSet<Tuple2<String, Integer>> counts =
text.flatMap(new LineSplitter())
.groupBy(0)
.sum(1).setParallelism(1);事实上,Flink 的每个算子都可以单独设置并行度。这也是我们最推荐的一种方式,可以针对每个算子进行任务的调优。
- 执行环境级别
我们在创建 Flink 的上下文时可以显示的调用 env.setParallelism() 方法,来设置当前执行环境的并行度,这个配置会对当前任务的所有算子、Source、Sink 生效。当然你还可以在算子级别设置并行度来覆盖这个设置。
复制代码
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(5);- 提交任务级别
用户在提交任务时,可以显示的指定 -p 参数来设置任务的并行度,例如:
复制代码
./bin/flink run -p 10 WordCount.jar- 系统配置级别
我们在上一课时中提到了 flink-conf.yaml 中的一个配置:parallelism.default,该配置即是在系统层面设置所有执行环境的并行度配置。
整体上讲,这四种级别的配置生效优先级如下:算子级别 > 执行环境级别 > 提交任务级别 > 系统配置级别。
在这里,要特别提一下 Flink 中的 Slot 概念。我们知道,Flink 中的 TaskManager 是执行任务的节点,那么在每一个 TaskManager 里,还会有“槽位”,也就是 Slot。Slot 个数代表的是每一个 TaskManager 的并发执行能力。
假如我们指定 taskmanager.numberOfTaskSlots:3,即每个 taskManager 有 3 个 Slot ,那么整个集群就有 3 * taskManager 的个数多的槽位。这些槽位就是我们整个集群所拥有的所有执行任务的资源。
总结
这一课时我们讲解了 Flink 中常见的分布式缓存、重启策略、并行度几个核心的概念和实际配置,这些概念的正确理解和合理配置是后面我们进行资源调优和任务优化的基础。在下一课时中我们会对 Flink 中最难以理解的“窗口和水印”进行讲解。