Flink系列文章
- 第01讲:Flink 的应用场景和架构模型
- 第02讲:Flink 入门程序 WordCount 和 SQL 实现
- 第03讲:Flink 的编程模型与其他框架比较
- 第04讲:Flink 常用的 DataSet 和 DataStream API
- 第05讲:Flink SQL & Table 编程和案例
- 第06讲:Flink 集群安装部署和 HA 配置
- 第07讲:Flink 常见核心概念分析
- 第08讲:Flink 窗口、时间和水印
- 第09讲:Flink 状态与容错
- 第10讲:Flink Side OutPut 分流
- 第11讲:Flink CEP 复杂事件处理
- 第12讲:Flink 常用的 Source 和 Connector
- 第13讲:如何实现生产环境中的 Flink 高可用配置
- 第14讲:Flink Exactly-once 实现原理解析
- 第15讲:如何排查生产环境中的反压问题
- 第16讲:如何处理Flink生产环境中的数据倾斜问题
- 第17讲:生产环境中的并行度和资源设置
你好,欢迎来到第 11 课时,这一课时将介绍 Flink 中提供的一个很重要的功能:复杂事件处理 CEP。
背景
Complex Event Processing(CEP)是 Flink 提供的一个非常亮眼的功能,关于 CEP 的解释我们引用维基百科中的一段话:
CEP, is event processing that combines data from multiple sources to infer events or patterns that suggest more complicated circumstances. The goal of complex event processing is to identify meaningful events (such as opportunities or threats) and respond to them as quickly as possible.
在我们的实际生产中,随着数据的实时性要求越来越高,实时数据的量也在不断膨胀,在某些业务场景中需要根据连续的实时数据,发现其中有价值的那些事件。
说到底,Flink 的 CEP 到底解决了什么样的问题呢?
比如,我们需要在大量的订单交易中发现那些虚假交易,在网站的访问日志中寻找那些使用脚本或者工具“爆破”登录的用户,或者在快递运输中发现那些滞留很久没有签收的包裹等。
如果你对 CEP 的理论基础非常感兴趣,推荐一篇论文“Efficient Pattern Matching over Event Streams”。
Flink 对 CEP 的支持非常友好,并且支持复杂度非常高的模式匹配,其吞吐和延迟都令人满意。
程序结构
Flink CEP 的程序结构主要分为两个步骤:
- 定义模式
- 匹配结果
我们在官网中可以找到一个 Flink 提供的案例:
DataStream<Event> input = ...
Pattern<Event, ?> pattern = Pattern.<Event>begin("start").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
return event.getId() == 42;
}
}
).next("middle").subtype(SubEvent.class).where(
new SimpleCondition<SubEvent>() {
@Override
public boolean filter(SubEvent subEvent) {
return subEvent.getVolume() >= 10.0;
}
}
).followedBy("end").where(
new SimpleCondition<Event>() {
@Override
public boolean filter(Event event) {
return event.getName().equals("end");
}
}
);
PatternStream<Event> patternStream = CEP.pattern(input, pattern);
DataStream<Alert> result = patternStream.process(
new PatternProcessFunction<Event, Alert>() {
@Override
public void processMatch(
Map<String, List<Event>> pattern,
Context ctx,
Collector<Alert> out) throws Exception {
out.collect(createAlertFrom(pattern));
}
});在这个案例中可以看到程序结构分别是:
第一步,定义一个模式 Pattern,在这里定义了一个这样的模式,即在所有接收到的事件中匹配那些以 id 等于 42 的事件,然后匹配 volume 大于 10.0 的事件,继续匹配一个 name 等于 end 的事件;
第二步,匹配模式并且发出报警,根据定义的 pattern 在输入流上进行匹配,一旦命中我们的模式,就发出一个报警。
模式定义
Flink 支持了非常丰富的模式定义,这些模式也是我们实现复杂业务逻辑的基础。我们把支持的模式简单做了以下分类,完整的模式定义 API 支持可以参考官网资料。
简单模式


联合模式

匹配后的忽略模式

源码解析
我们在上面的官网案例中可以发现,Flink CEP 的整个过程是:
- 从一个 Source 作为输入
- 经过一个 Pattern 算子转换为 PatternStream
- 经过 select/process 算子转换为 DataStream
我们来看一下 select 和 process 算子都做了什么?
可以看到最终的逻辑都是在 PatternStream 这个类中进行的。
public <R> SingleOutputStreamOperator<R> process(
final PatternProcessFunction<T, R> patternProcessFunction,
final TypeInformation<R> outTypeInfo) {
return builder.build(
outTypeInfo,
builder.clean(patternProcessFunction));
}最终经过 PatternStreamBuilder 的 build 方法生成了一个 SingleOutputStreamOperator,这个类继承了 DataStream。
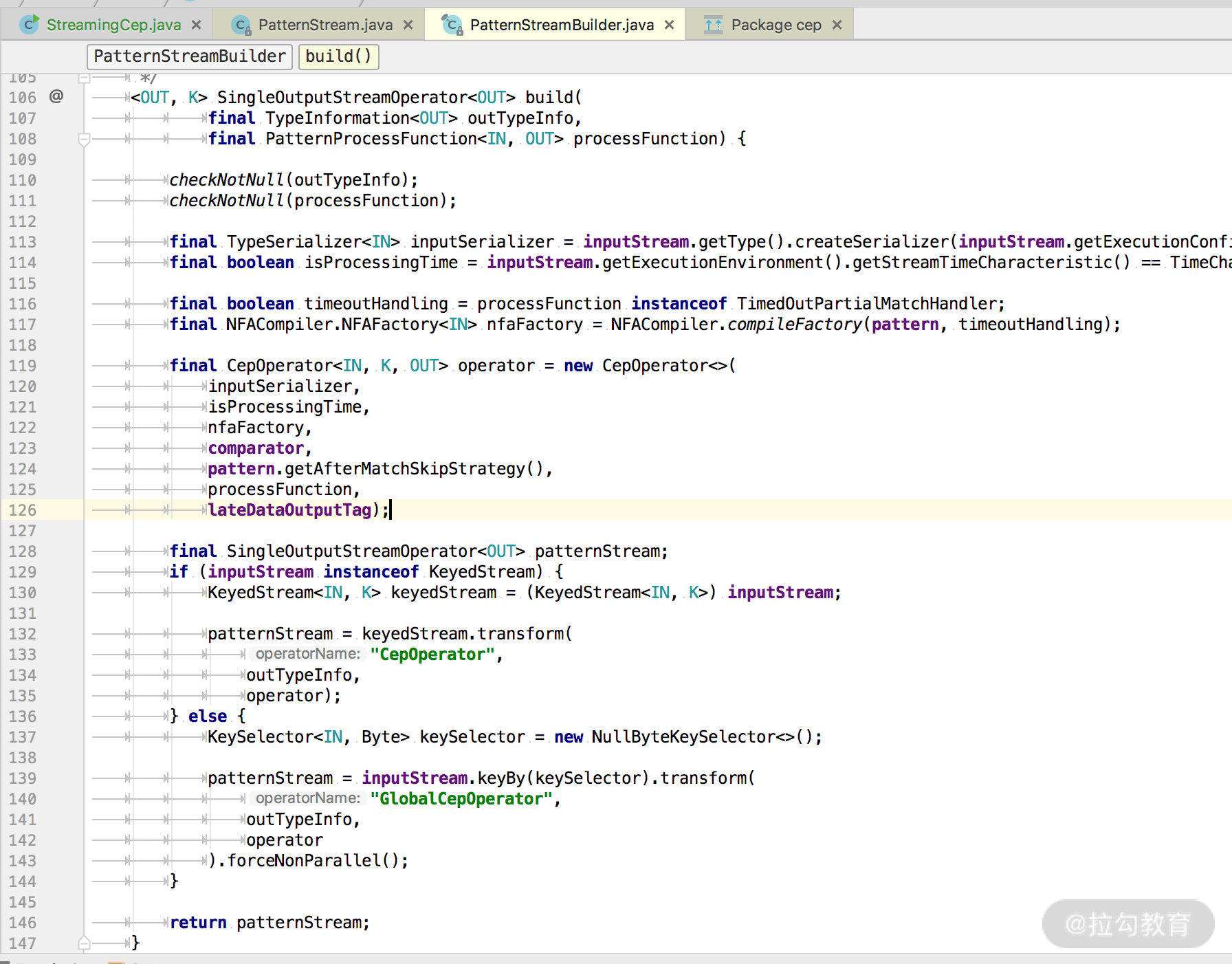
最终的处理计算逻辑其实都封装在了 CepOperator 这个类中,而在 CepOperator 这个类中的 processElement 方法则是对每一条数据的处理逻辑。
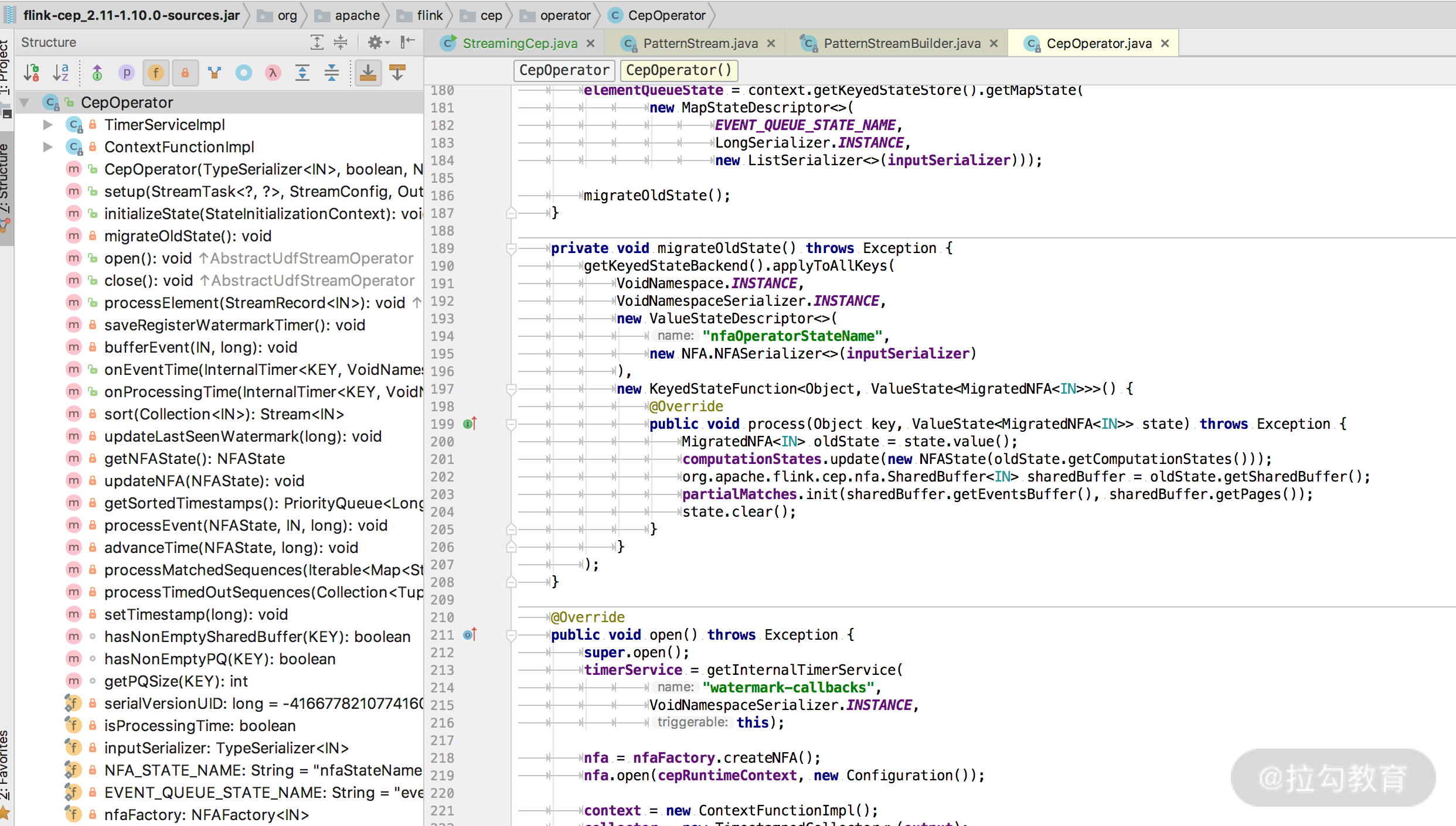
同时由于 CepOperator 实现了 Triggerable 接口,所以会执行定时器。所有核心的处理逻辑都在 updateNFA 这个方法中。
入口在这里:
private void processEvent(NFAState nfaState, IN event, long timestamp) throws Exception {
try (SharedBufferAccessor<IN> sharedBufferAccessor = partialMatches.getAccessor()) {
Collection<Map<String, List<IN>>> patterns =
nfa.process(sharedBufferAccessor, nfaState, event, timestamp, afterMatchSkipStrategy, cepTimerService);
processMatchedSequences(patterns, timestamp);
}
}NFA 的全称为 非确定有限自动机,NFA 中包含了模式匹配中的各个状态和状态间的转换。
在 NFA 这个类中的核心方法是:process 和 advanceTime,这两个方法的实现有些复杂,总体来说可以归纳为,每当一条新来的数据进入状态机都会驱动整个状态机进行状态转换。
实战案例
我们模拟电商网站用户搜索的数据来作为数据的输入源,然后查找其中重复搜索某一个商品的人,并且发送一条告警消息。
代码如下:
public static void main(String[] args) throws Exception{
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource source = env.fromElements(
//浏览记录
Tuple3.of("Marry", "外套", 1L),
Tuple3.of("Marry", "帽子",1L),
Tuple3.of("Marry", "帽子",2L),
Tuple3.of("Marry", "帽子",3L),
Tuple3.of("Ming", "衣服",1L),
Tuple3.of("Marry", "鞋子",1L),
Tuple3.of("Marry", "鞋子",2L),
Tuple3.of("LiLei", "帽子",1L),
Tuple3.of("LiLei", "帽子",2L),
Tuple3.of("LiLei", "帽子",3L)
);
//定义Pattern,寻找连续搜索帽子的用户
Pattern, Tuple3> pattern = Pattern
.>begin("start")
.where(new SimpleCondition>() {
@Override
public boolean filter(Tuple3 value) throws Exception {
return value.f1.equals("帽子");
}
}) //.timesOrMore(3);
.next("middle")
.where(new SimpleCondition>() {
@Override
public boolean filter(Tuple3 value) throws Exception {
return value.f1.equals("帽子");
}
});
KeyedStream keyedStream = source.keyBy(0);
PatternStream patternStream = CEP.pattern(keyedStream, pattern);
SingleOutputStreamOperator matchStream = patternStream.select(new PatternSelectFunction, String>() {
@Override
public String select(Map>> pattern) throws Exception {
List> middle = pattern.get("middle");
return middle.get(0).f0 + ":" + middle.get(0).f2 + ":" + "连续搜索两次帽子!";
}
});
matchStream.printToErr();
env.execute("execute cep");
} 上述代码的逻辑我们可以分解如下。上述代码的逻辑我们可以分解如下。首先定义一个数据源,模拟了一些用户的搜索数据,然后定义了自己的 Pattern。这个模式的特点就是连续两次搜索商品“帽子”,然后进行匹配,发现匹配后输出一条提示信息,直接打印在控制台上。
可以看到,提示信息已经打印在了控制台上。
总结
这一课时讲解了 Flink CEP 的支持和实现,并且模拟了一下简单的电商搜索场景来实现对连续搜索某一个商品的提示,关于模式匹配还有更加复杂的应用,比如识别网站的用户的爆破登录、运维监控等,建议你结合源码和官网进行深入的学习。